| [ГЛАВНАЯ] [БИБЛИОТЕКА] [БИБЛИОГРАФИЯ] [ФОРУМ] |
Л.И.Бородкин
|
|
Введем критерий близости исследуемого текста к i-му тексту (i = 1, ..., m) как отношение числа общих для данных двух текстов узлов к суммарному количеству узлов для этих двух текстов: Как видно из формулы (1), значение коэффициента Чем больше доля их общих узлов, тем ближе значение Для описания методики выявления авторских особенностей стиля нам потребуется ввести понятие общего графа G (X, U) для данной совокупности графов Gi(X,Vi) (i = 1,..., k). Множество дуг U общего графа G (X, U) определим как пересечение множеств Vi(i = 1,...,k): U = Введем также коэффициент qi, близости каждого из графов G (X,Vi) (i = 1, ..., k) к общему графу G (X, U) как отношение числа дуг, общих для графов Gi(X,Vi) и G (X, U), к числу дуг графа Gi(X,Vi): qi=|Vi Коэффициент q изменяется в преде-лах 0 Еще одна модификация методики атрибуции связана с идеей построения "динамической выборки" текста атрибутируемого произведения. В этом случае выделяется достаточно большой фрагмент текста, и первая выборка совпадает с началом этого фрагмента. Далее граница выборки фиксированной длины "скользит" внутри фрагменты по ходу развертывания текста, каждый раз "перекрывая" частично предыдущую выборку. Тем самым удается проследить динамику и степень изменений большого фрагмента анализируемого текста и оценить его однородность. Для пояснения смысла коэффициентов |
 |
 |
 |
|
Определим узел графа как такую вершину, в которую входит не менее трех дуг. Тогда множество узлов графа G1 составляют вершины 2 и 5, графа G2 - вершины 2 и 4, а графа G3 - 2, 5 и 3 Перепишем формулу (1) в более простом виде:
Таким образом, наиболее близкой (по критерию
где Ni0 - число общих дуг на графах Gi, G0. G0 - общий граф; Ni - число дуг на графе Gi . Определим G0 - общий граф для G1, G2 G3.
Вычисления по формуле (4) приводят к следующим результатам сравнения структурной близости каждого из графов G1, G2, G3 с общим графом G0 :
Самым близким (по критерию q) к общему графу оказывается граф связей первого текста, самым далеким - третьего. Обобщив формулу (4), можно ввести в рассмотрение коэффициент ~qij , измеряющий близость структуры любой пары графов Gi и Gj, как отношение числа дуг, общих для графов Gi и Gj, к суммарному числу различающихся дуг для рассматриваемой пары текстов:
Вычисления по формуле (5) дают следующие значения для сравнения структурной близости G1, G2и G3:
Ближе всего по совокупности связей оказываются первый и второй тексты, дальше всего - второй и третий. Описанные методики были реа-лизованы в виде программ для ЭВМ. В 1973 г. была разработана программа для большой ЭВМ (БЭСМ-6) (на языке ФОРТРАН), и вплоть до 1988 г. обработка текстового материала производилась с помощью этой программы на ВЦ АН СССР и в НИВЦ МГУ. В 1989 г. была создана новая версия этой программы для персональных компьютеров, совместимых с IBM PC/AT, и с этого времени обработка текстов велась в лаборатории исторической информатики кафедры источниковедения Исторического факультета МГУ. Предложенная нами методика атрибуции была использована позднее другими авторами в задачах определения авторства различных текстов. Так, данный метод применялся Е. В. Злобиным при анализе "Записок" декабриста И. И. Горбачевского, члена общества "Соединенных славян" [5]. Авторство "Записок" долгое время вызывало споры. Итоги компьютерной обработки текстового материала не подтвердили принадлежности "Записок" перу И. И. Горбачевского. Частоты взаимной встречаемости грамматических форм и графы сильных связей использовались А.В.Быстровым и Е.В.Злобиным в задаче атрибуции предсмертного письма Б.В.Савинкова [6]. Сравнительному анализу подверглись тексты Б.В.Савинкова и Я.Г.Блюмкина и собственно предсмертное письмо. Сочетание выводов, полученных с помощью компьютерного анализа, и результатов традиционного атрибутирования позволило отклонить гипотезу об авторстве Блюмкина. Другой пример использования описанной выше методики атрибуции характеризует ее возможности при исследовании галльских панегириков [7]. Речь идет о работе И.Ю.Шабаги, изучавшей тексты сборника "XII Panegyrici Latini", являющегося од-ним из крупнейших источников по истории Поздней Римской империи. Первая из входящих в него речей - "Панегирик" Плиния Младшего императору Траяну (100 г.). Остальные 11 речей принадлежат галльским ораторам III - IV вв. и посвящены различным императорам. Авторы пяти панегириков известны (их имена сохранились в заголовках или в текстах речей); остальные шесть речей сборника не атрибутированы. Выделив для анализа галльских панегириков 40 грамматических классов, И. Ю. Шабага выявила "общеязыковое ядро" панегириков; его составляли как связи, присущие структуре латинского языка, так и связи, отражающие стилистические особенности панегирического жанра. Удаление общеязыкового ядра сохранило большую структурную близость галльских панегириков; коэффициент близости, измеряющий отношения совпадающих дуг в графах сильных связей каждой пары речей к общему их числу в том и другом панегирике, колебался от 0.14 до 0.35 на всем массиве анализируемых текстов. |
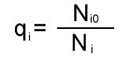 , (4)
, (4)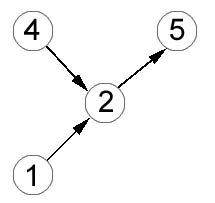
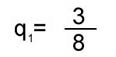 ;
;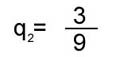 ;
;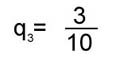
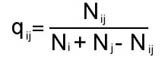 , (5)
, (5)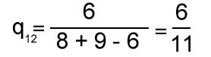 ;
;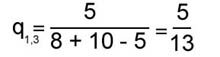 ;
;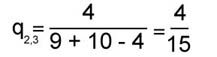
|
Полученные результаты позволили автору работы сделать вывод о принадлежности второго и третьего панегириков одному автору - Мамертину и показали несостоятельность теории О. Зеена, уже более 100 лет приписывающей IV, VI, VII, VIII и IX панегирики перу Евмения - автора V панегирика. Как следует из результа-тов применения методики атрибуции, каждая из пяти указанных анонимных речей сборника принадлежит отдельному автору. Таким образом, накапливающийся опыт использования предложенной методики атрибуции текстов дает основания говорить о широком диапа-зоне ее возможностей, имея в виду временной, пространственный и жанровый аспекты проблемы атрибуции. ПРИМЕЧАНИЯ 1. Фукс В. По всем правилам искусства (точные методы в исследованиях литературы, музыки и изобразительного искусства // Искусство и ЭВМ. М., "Мир", 1975. Гл.VI. К тексту 2. Эти дополнительные пункты таковы: 2а) Сравнивая полученные совокупности грамматических связей, выделя-ем так называемое общеязыковое ядро, т.е. набор таких связей, которые содержатся во всех (или почти во всех) текстах. 26) Сформированное "общеязыковое ядро" удаляется из каждой совокупности отобранных грамматических связей с высокими частотами; оставшиеся после этого "существенные" статистические связи каждой совокупности уже в большей мере характеризуют авторский стиль. К тексту Так называемое общеязыковое ядро в исследованиях разного масштаба играет разную роль. При исследовании произведений одного автора - это наиболее характерные особенности его стиля. При исследовании произведений определенного жанра, но разных авторов - это черты, свойственные прежде всего жанру, и т.д. 3. См. пример в главе I.К тексту 4. Очевидно, понятие общего графа совпадает с введенным ранее понятием "общеязыкового ядра" при l = m. К тексту 5. 3лобин Е.В. К вопросу об авторстве "Записок" И.И.Горбачевского // История СССР. № 2. С.140-155.К тексту 6. Быстров А.В., 3лобин Е.В. К вопросу об авторстве предсмертного письма Б.В.Савинкова - опыт комплексного исследования // Круг идей: Новое в исторической информатике. М., 1994. С.129-133. К тексту 7. Шабага И. Ю. Опыт исследования галльских панегириков количественными методами // Вестник Древней истории. 1993. № 1. С.147-161. К тексту |
| [В НАЧАЛО] [ГЛАВНАЯ] [БИБЛИОТЕКА] [БИБЛИОГРАФИЯ] [ФОРУМ] |