НОВОЕ ОРУДИЕ ОБЪЕКТИВНОГО ИССЛЕДОВАНИЯ ДРЕВНИХ ДОКУМЕНТОВ.
|
|
| Язык является как бы летописью культурной и социальной истории человечества. В. Богородицкий. |
|
I |
|
Чтобы выяснить сразу то, что я хочу здесь сказать, рассмотрю несколько примеров. Возьмем хотя бы в нашем русском языке два легко заменимые Друг другом слова: "mak kak” и "потому что”. Почти в каждой фразе одно из них можно заменить другим с сохранением первоначального смысла, и потому в переводе на иностранный язык такое различие в складе речи исчезает, между тем как в оригинале одни авторы могут машинально употреблять почти исключительно первую из этих “служебных частиц речи”, редко вспоминая о существовании второй, другие же авторы поступят совершенно наоборот. Точно также слово иной большинством современных авторов, хотя и не всеми, постоянно заменяется словом другой. Одни авторы часто прибегают к слову komopый, другие же его не любят и заменяют причастной формой глагола, который пришлось бы поставить за ним. Одни часто употребляют служебную частицу между, другие пишут вместо нее: среди или средь. У одних фраза длинная, с постоянными придаточными предложениями, у других - короткая; у одних очень часты деепричастия, а у других их почти совсем нет. Одни постоянно прибегают к помощи слова этот, другие часто заменяют его словом тот и т. д., и т. д. Все эти различия в нашем складе речи обусловливаются чисто машинальными причинами, целым рядом предыдущих внешних и внутренних лингвистических влияний, ушедших у нас уже давно в область бессознательного. Вот почему служебные частицы речи с таким же правом можно бы назвать и распорядительными. Они не только служат, но и распоряжаются нашей речью.
Именно эти предыдущие влияния чаще или реже напоминают нам то или другое из известных нам слов, как в письме, так и в живом разговоре, и потому мы нередко встречаем людей, против собственной воли постоянно произносящих какое-нибудь присловие в роде: понимаете, или то-есть, или mak сказать, а иногда и какое-нибудь сложное вставное изречение.
В письме это, понятно, сглаживается, так как человек всегда может обдумать фразу прежде, чем писать ее, а в печати искусственная обработка естественного склада речи достигает нередко очень больших размеров.
Все авторы печатают свои произведения с так называемыми корректурными поправками, где заботливо разрежают частящие слова, в особенности, если они попадаются по два раза в той же самой фразе. Однако, подобные поправки производятся обязательно лишь тогда, когда естественный склад речи автора, вследствие слишком частого употребления излюбленных им служебных частиц, делается неуклюжим, не литературным. Поэтому даже и печатание не окончательно уничтожает особенности естественного склада речи писателя. Именно потому, когда автор нам хорошо известен по прежним его произведениям, мы легко угадываем его и в новых, в особенности, если нам прочтут достаточно длинный отрывок.
Однако, чисто субъективный, основанный лишь на индивидуальной чуткости, способ отгадывания авторов не может иметь серьезного научного значения, так как он не дает безусловных доказательств, обязательных для каждого. Вот почему исследователи литератур уже давно хотели найти такой метод, при помощи которого индивидуальности скслада речи выступали бы объективно.
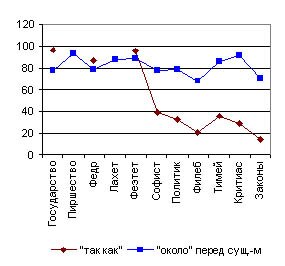
Попытки отыскать такой метод делались не раз. Особенно много, как мы увидим далее, применялось изучение слога к диалогам, приписываемым Платону, но именно этот выбор и сбил, мне кажется, возникавшую стилеметрию с верного пути. В виду того, что не только подлинных рукописей Платона, или его ранних цитаторов, но даже и средневековых копий с них нигде нет, исследователи их слога признали своим основным положением, что все приписываемые Платону диалоги, имеющиеся в первых печатных (т.-е. с XV века нашей эры) изданиях, должны быть признаны подлинными и хорошо сохраненными в продолжение двух тысяч лет их неведомого для пас существования, если они удовлетворяют следующим условиям:
1) когда о них имеются более или менее детальные и многочисленные упоминания в печатных же изданиях других греческих или латинских авторов, находящихся в тех же условиях долгой иеведомостп для нас, и 2) когда сами диалоги не содержат явных анахронизмов.
Но может ли считаться вполне научным исходное положение, которое сводится к тому, что всякое произведение классического писателя, имеющееся лишь в печатных изданиях или в редких рукописях эпохи Возрождения, должно считаться подлинным его произведением, если не доказана его подложность? Конечно, нет! Скорее можно требовать обратного, в виду такого долгого промежутка его неведомости для нас. Сходство словаря и грамматики не может считаться достаточным доказательством достоверности, так как в эпоху Возрождения ученые хорошо владели и греческим, и латинским языками и, - kak говорят сами их исследователи, - “искусно подделывали произведения почти всех древних авторов”.
Исходное положение о подлинности главнейших произведений Платона привело к тому, что в особенностях слога и даже образа мыслей, замечаемых в различных произведениях, припи-сываемых Платону, искали не доказательства различия их авто-ров, а исключительно различия в слоге и миросозерцании самого Платона в различные возрасты его жизни, хотя уже по противо-положности идеалов и мировоззрения между многими из них можно было бы заключить, что имя “Платон” (как и Гомер) было символом целой школы, в котором потонула первоначаль-ная личность. Различия в слоге различных произведений "Платона” оказались так велики, что покрыли собою колебания в слоге других однородных с ним авторов, и таким образом сразу лишили зарождавшуюся стилеметрию всякого практического значения. Этому же способствовало и то, что границы ее области были отодвинуты платонистами далеко за их естественные пределы. Вместо того, чтоб подсчитывать общеупотребительные, часто встречающиеся в языке, служебные частицы, начали, наоборот, обращать внимание на редкие выражения, на необычные формы, да и в подсчете обычных служебных частиц не соблюдалось никакого общего масштаба. Подсчеты вели обыкновенно на страницу того или иного издания, и цифры давались в таком виде, что соотношения их по величине не представлялись наглядными.
Вот почему еще много лет тому назад (в средине 80-х годов) мне пришла в голову мысль вывести общие стилеметрические законы сначала на современных авторах, единоличность которых несомненна, при чем, отбросив все редкие слова, ограничиться наиболее частыми и общими для всех родов литературы. Если, думалось мне, в природе и в обычной жизни человека все очень многократные события, кажущиеся случайными, принимают при достаточном числе повторений закономерный характер, то почему же этого ие может быть и в области речи? Ведь даже число ежегодно посылаемых писем в любом почтамте, несмотря на явную произвольность их писания, оказывается почти постоянным. Больше того: и самое число писем, на адресе которых забыто что-нибудь, как, например, название города, или имя адресата, или номер дома на улице, - ежегодно постоянно или подвергается определенной эволюции в зависимости от спокойного или тревожного настроения общества. Да и в самих наших человеческих языках все их элементы, как мы видели уже, имеют определенную пропорцию.
Конечно, обычные имена существительные, прилагательные и глаголы зависят от содержания книги. В зоологии будут часто встречаться имена животных и частей их тела, в химии имена реагентов и химических реакций, совсем не употребительные в обычном языке. В истории народов будут часты собственные имена различных деятелей и географические названия. Глаголы здесь будут употребляться, главным образом, в прошлом времени, тогда как в естественных науках в настоящем. Местоимение я будет чаще встречаться в рассказах, излагаемых от имени первого лица. Местоимения он и она, во всех их падежах, будут часты в обычном романе...
Значит, частота употребления таких слов ничего
нам не скажет (3). Однако, даже и при разнородности сюжетов, есть во всех языках ряд слов, которые употребляются почти одинаково во всех родах литературы и которые по своему характеру могут быть названы, как я уже выражался ранее, служебнымиили распорядительными частицами человеческой речи. Это прежде всего союзы, предлоги и отчасти местоимения и наречия, а затем и некоторые вставные словечки, в роде: “т.-е.”, “например”или “и mak далее”. Затем идут деепричастные и причастные окончания, как задние приставные частицы, характеризующие среднюю сложность фразы у того или другого автора. Даже и самые знаки препинания могут быть названы в этом случае попутными(или паузными) распорядительными частицами всех человеческих. языков.Нетрудно видеть при самом беглом статистическом подсчете, что каждая из этих частиц тоже имеет свою собственную частоту повторения. Возьмем хотя бы отрицание не. Подсчитайте - и вы увидите, что на каждую тысячу отдельных слов у Толстого оно встречается обыкновенно немного менее 20 раз, у Пушкина и Гоголя около 20-ти, а у Тургенева значительно более, чем у них, иногда свыше 30 раз. В общем же колебания ее заключаются в промежутке от 12-ти до 35 раз на тысячу слов в зависимости от склонности того или иного автора к отрицаниям. Все это показывает, что служебная частица “не” в большой мере подвержена индивидуальным колебаниям, т.е. определяет склад речи автора. То же самое и в случае подсчета остальных служебных частиц. Подобно тому, как каждый автор, всегда оставаясь человеком, имеет свою индивидуальную физиономию, так и его язык, все время оставаясь русским, или английским, или французским, обнаруживает свои особенные черты, проявляющиеся в большем или меньшем пристрастии данного автора к тем или иным распорядительным частицам.
II
Нельзя ли по частоте таких частиц узнавать авторов, как-будто по чертам их портретов?
Для этого прежде всего надо перевести их на графики, обозначая каждую распорядительную частицу на горизонтальной линии, а число ее повторения на вертикальной, и сравнить эти графики между собой у различных авторов.
Еще в первые годы моей сознательной жизни, задолго до того, как я познакомился с трудами Гомперца и других стилеметристов, мне пришла такая идея и даже ясно представились ее вероятные детали. Мне было ясно, что у авторов различных эпох такие графики в некоторых служебных частицах должны сильно различаться. Возьмем хотя бы частицу ибо, часто встречающуюся в русском языке еще в первой четверти XIX века. Очевидно, что вместо нее на графике современных нам писателей будет зияющая зазубрина, так как ее теперь нет. Точно также слово весьма оставит вместо себя пустоту, потому что оно заменилось теперь почти нацело словом очень, и т. д., и т. д.
Даже у современных друг другу писателей должны появляться свои оригинальные зазубрины, свойственные лишь им одним, благодаря антипатии того или другого автора к той или другой служебной частице.
Все это, думалось мне, делает такие графики подобными световым спектрам химических элементов, в которых каждый элемент характеризуется своими особыми зазубринами, так что астроном легко и надежно определяет по ним химический состав недоступных нашим летательным аппаратам небесных светил.
Тогда же мне пришла в голову и мысль назвать подобные графики лингвистическими cnekmрaми, и исследование по ним авторов назвать лингвистическим анализом, соответственно спектральному анализу состава небесных светил.
Однако, разработать эти идеи мне было долго невозможно в Шлиссельбургской крепости, где они впервые пришли мне в голову, хотя в последние годы мне вновь пришлось возвратиться там невольно к этому предмету. Астрономическое исследование Апокалипсиса и библейских пророков привело меня по имеющимся там астрономическим данным к неожиданному для меня самого заключению, что черновик этой книги написан в промежуток от 30 сентября по 1 октября 395 года нашей эры, а библейские пророки еще позднее: в V веке нашей же эры. Это приводило меня к выводу, что все дошедшие до нас сочинения “Иоанна Хризостома”, “Оригена”, “Тертулиаиа” и других христианских авторов первых четырех веков нашей эры апокрифичны, так как они упоминают и об Апокалипсисе, и о пророках.
|
Каждый литературно-образованный человек знает, что все оригинальные авторы отличаются своим складом речи, даже и в том случае, когда мы сравниваем их с писателями того же самого поколения. Мы русские легко отличаем, например, склад. речи Гоголя от склада речи Пушкина или Тургенева. В английской литературе склад речи Теккерея совсем не похож на склад речи Диккенса, и в них обоих чувствуется еще большее различие от склада речи Киплинга или Бретгарта, как принадлежащих к следующему поколению. Спешу отметить, что я говорю здесь только о складе речи, а никак не о складе мысли, который тоже различен у каждого оригинального писателя. Склад мысли сохраняется даже и в переводе на иностранные языки, тогда как склад речи почти теряется, заменяясь складом речи переводчика, да и в подстрочниках, каковы, например, старинные переводы религиозных книг, первоначальный склад речи во многих существенных деталях исчезает. Вот почему то, о чем я хочу здесь писать, лишь соприкасается с той стилеметрией, зародыши которой мы находим у Гомперца, Лютославского и др., разрабатывавших слог Платона и некоторых других греко-латинских |
Прежде всего сейчас же обнаружились некоторые резкие оригинальности.
У Карамзина в беллетристических произведениях очень часто употребляется восклицание “Ах!”, почти совершенно отсутствующее у Гоголя, Пушкина, Толстого, Тургенева и Загоскина.
Служебная частица “было” (например, чуть-было)-только у Пушкина; “близ”-только у Тургенева (у других “около”); “ведь” - отсутствует у Карамзина и Загоскина; “вдруг” и “даже”-редки у Толстого; “еле”-только у Гоголя; “заместо”- только у Тургенева; “ибо”-еще употребляется часто Карамзи-ным и Гоголем, изредка Пушкиным, но уже совсем отсутствует у Толстого, Тургенева и Загоскина; “коли” (вместо “если”)- часто у Толстого в речи простых людей, но нет у Тургенева и у других; “может” (без “быть”)-только у Гоголя; “нежели”- только у Пушкина; “оттого”-у Толстого; “про” (например, “про него”) - довольно часто у Гоголя, Толстого и Пушкина и отсут-ствует у Тургенева и Загоскина; “против” - часто у Гоголя; “подле” (вместо “рядом”) - у Загоскина; “среди” (вместо “между”) - у Гоголя и Карамзина; “словно” - часто у Толстого; “точно”-у Тургенева; “через”- часто у Пушкина; “этак”- только у Гоголя.
А в числе употребляемых ими служебных частиц (союзов и предлогов) оказались ясные процентные различия (слоговые типы).
Чтоб не давать очень сложных общих спектров при нанесении этих цифр на графики, я разделил их здесь на предложные, союзные, местоименные cnekmpы и т. д., судя по тому, что они представляют.
Наиболее часто повторяющимися оказались у всех русских авторов
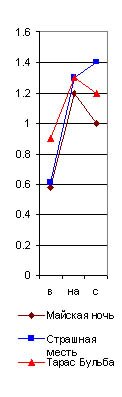
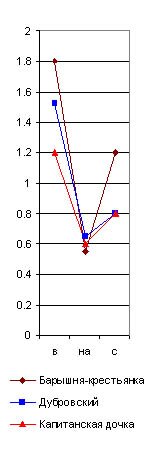
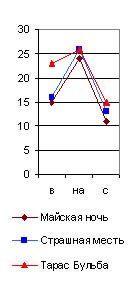
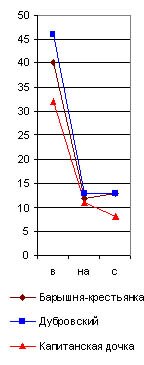
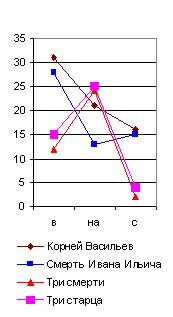
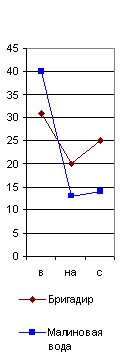
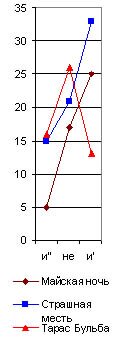
предлоги в, на(5)с, почему их графики я и назвал главным предложным cnekmpом. Они даны на рис. 29 (6), из которого читатель и без цифр видит по вертикальному ряду чисел, что на тысячу слов у Гоголя предлог в повторился в “Тарасе Бульбе” 23 раза, в Майской ночи” 15, а в “Страшной мести" 16 раз; предлог на повторился 24 раза в “Майской ночи” и 26 в “Бульбе” и “Страшной мести” и т. д. А когда я соеди-нил эти точки линиями, то во всех (взятых мною совершенно случайно) трех произведениях Гоголя получились очень сходные ломаные линии в виде острых крыш с ясным преобладанием предлога на над бис (см. рис. 29). У Пушкина же во всех трех (взятых мною также совершенно случайно) произведениях, наоборот, оказалось, на такую же тысячу слов, сильное преобладание предлога внад предлогами наи с, почти равными по частоте своего повторения.|
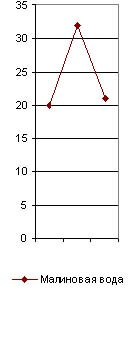
Идея об исследовании их лингвистическим анализом сама собой пришла мне в голову. Но для этого необходимо было прочно установить основные приемы такого анализа на современных общеизвестных авторах, показав, что каждый из них обладает какими-либо особенностями в своем лингвистическом спектре. Однако, мое время так было заполнено другими делами, что только летом 1915 г. я нашел несколько свободных дней, чтобы составить лингвистические спектры хотя бы нескольких писателей. Я взял сначала Гоголя (“Майскую ночь”, “Страшную месть” и “Тараса Бульбу"), Пyшkuнa (“Капитанскую дочку”, “Дубровского” и “Барышню-крестьянку”), Толстого (“Смерть Ивана Ильича”, “Корнея Васильева”, “Три смерти” и “Три старца”), Тургенева (“Малиновую воду”), Карамзина (“Бедную Лизу”) и Загоскина (“Юрия Милославского”). В каждом из этих рассказов я отсчитывал (исключая эпиграфы или вводные цитаты из посторонних авторов) первую тысячу слов, подчеркивая в ней красным карандашом все служебные частицы, а потом сосчитывал |
 |
 |
 |
 |
|
|
|||
Отсюда ясно, что по одному простому взгляду на главный предложный спектр какого-либо произведения Пушкина, по недоразумению приписанного Гоголю, мы заподозрили бы неправильность такого утверждения и сделали бы дoгaдky о принадлежности его Пушкину, хотя еще и не решили бы этим дела окончательно.
Действительно, сравнивая на нашей графике главный предложный спектр Пушкина с таким же спектром “Малиновой воды” Тургенева (в последней колонке рис. 29), мы видим, что они очень сходны, и потому для отличия Тургенева от Пушкина главный предложный спектр негоден и надо искать других.
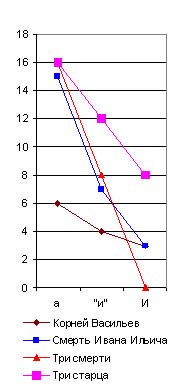
Да и вообще нельзя решать вопроса об авторстве по какому-либо одному небольшому спектру, в роде взятого нами и состоящего лишь из трех членов. Необходимо составить очень длинный многочленный спектр, или несколько коротких, но разнородных по своему содержанию спектров, и это тем более необходимо, что не всякий член спектра абсолютно постоянен у данного автора по частоте своего употребления. Здесь в полной мере господствует закон случайных отклонений от средней нормы, дающей вместо средней частоты употребления вариационную с размахом АВ, который, однако, тем более суживается, чем больше тысяч слов отсчитано нами в исследуемом отрывке, т.-е. если при числе N слов (рис. 30) вариационный криволинейный треугольник будет иметь вид АВС, то при числе 2N слов он получит вид A1В1C1, а при большем числе слов его основание еще больше сузится за счет вырастающей высоты, так как площадь его всегда одна и та же, если перечислена на промилли (пли на проценты).
 |
|
|
|
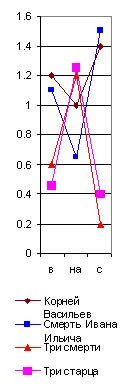
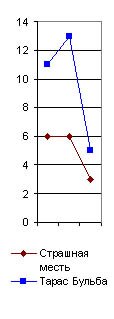
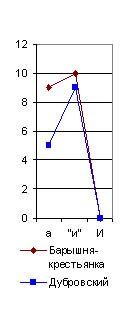
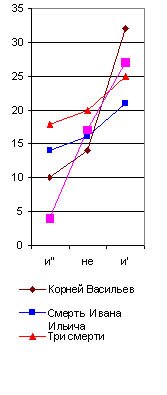
Но и при меньшем числе слов неправильное определение по причине значительной величины вероятной ошибки возможно лишь тогда, когда мы исследуем только три - четыре распорядительные частицы, а при десятке их всегда обнаружится общий характер лингвистического спектра для данного писателя. Особенно обязательно это для старых авторов рукописного периода, которые не могли десятки раз “исправлять свой слог в корректурах”, заменяя другими как раз те распорядительные частицы, которые для них слишком привычны. Очень интересно отметить, например, что те самые члены главного предложного спектра (в, на, с), которые обнаружили постоянство у Пушкина и у Гоголя, совсем не обнаруживают этого у Толстого, и главный предложный спектр у него является в двух вариациях. Первая (например, в “Смерти Ивана Ильича” и в “Корнее Васильеве”) напоминает спектр Пушкина, хотя и с несравненно меньшим числом частицы в (рис. 29), а вторая вариация (например, в “Трех смертях” и “Трех старцах”) напоминает Гоголя, но с несравненно меньшим числом предлога с. Здесь является вопрос: отчего зависит это расчленение главного лингвистического спектра Толстого на два типа? Оттого ли, что он сильно корректировал свои произведения и этим сделал свой главный предложный спектр неопределенным, пли те перевороты, которые он переживал в своем мировоззрении и направлении своего творчества, отзывались и на слоге его речи? Конечно, у каждого автора, писавшего более полувека, лингвистический спектр не может оставаться все время совершенно неизменным. Он должен подвергаться медленной эволюции, как и световые спектры физических тел, изменяющиеся по мере повышения температуры. Однако, у Толстого обе вариации так резко различились на приведенных мною графиках, что наводят на мысль о специальной корректурной обработке автором их частоты, и исследование в этом отношении всех других его произведений является в высшей степени желательным. Перейдем теперь к другим спектрам тех же писателей в тех же их произведениях. Рассмотрим, например, один из многих возможных союзных cnekmpoe (рис. 31). Я взял для его составления, как видно по таблице, сначала союз а, затем союз и, когда он употребляется в выражениях в роде “был и он”, “я и знал”, т.-е. служит не обозначением конца перечня, а чисто слоговой приставкой, вследствие чего я и поставил его в кавычках (“и”). Затем я взял тот же союз и в начале фраз, когда он пишется с большой буквы. В спектре Библии этот член дал бы преобладание над предыдущими, а у взятых мною писателей он всегда в минимуме, как видно по его графике. Этот спектр тоже оказался различен у них всех. У Гоголя и Пушкина здесь преобладает слоговое "и”, у Толстого же “а”; кроме того, Пушкин отличается от Гоголя почти полным отсутствием библейского предфразного И (как оно употребляется во фразах в роде: “И был вечер, и было утро”, “И пошел Иисус” и т. д.). |
 |
 |
 |
|
|
||
Спектр пз наиболее часто встречающихся местоимений: этот, свой, тот оказался уже несоставимым у современных писателей при подсчете только одной тысячи слов, так как этих местоимений у них оказалось лишь по нескольку на тысячу, а малое количество повторений какого-либо случайного фактора, как известно из статистики, не дает возможности для вывода в нем закономерностей, благодаря уже отмеченному мною закону случайных отклонений от средней нормы тем более широких, чем меньше взято слов для подсчета. Для того, чтобы местоименные и другие спектры дали достаточно типичные графики, нужно подсчитать их число по крайней мере среди пяти тысяч слов (а потом разделить полученную цифру на пять, с целыо приведения их к однородности с вышеприведенными спектрами).
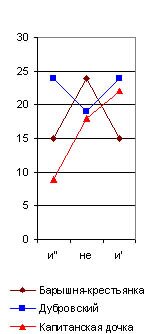
Но, даже и при значительной частоте повторения некоторых служебных частиц речи, могут обнаруживаться, как мы уже видели у Толстого, значительные колебания их числа в различных произведениях того же самого автора, если мы будем брать всего лишь тысячу слов. Образчиком такого неопределенного спектра является, между прочим, и приводимый мною на рис. 32, где я сопоставил отрицательную частицу не с союзом и, в его двух вариациях: первая (и") соединяет между собою существительные или прилагательные имена, вторая (и") - глаголы или пелые фразы. Мы видим, что колебания их числа в различных произведениях у того же самого автора настолько же резки, как и у двух различных писателей. Однако и тут могут найтись авторы, у которых этот спектр обнаружит явное постоянство во всех произведениях.
 |
 |
 |
 |
|
|
|||