| [СПИСОК ПУБЛИКАЦИЙ] [ГЛАВНАЯ] [ПЕРСОНАЛИИ] [ФОРУМ] |
Е. И. Горошко
Интегративная модель
свободного ассоциативного эксперимента
ГЛАВА 2 ПРОБЛЕМЫ АССОЦИАТИВНОЙ ЛЕКСИКОГРАФИИ
В последнее время собирание ассоциативных норм и создание на их основе ассоциативных словарей и тезаурусов стало одним из приоритетных направлений в психолингвистических исследованиях.
Под ассоциативным словарем понимается некоторая совокупность ассоциативных норм, полученная путем проведения ассоциативного эксперимента по определенному списку стимульных слов. Иными словами, модель ассоциативного словаря представляет некую упорядоченную последовательность (совокупность) ассоциативных полей, полученных в результате проведения САЭ. Как правило, под ассоциативной нормой понимается совокупность реакций, собранная примерно от группы информантов размером 1000 человек, но иногда этот объём может быть “сужен” и до 500 – 700 человек, а при некоторых исследовательских задачах – допускаются ассоциативные поля объемом и до 100 единиц.
Ассоциативные словари относятся к словарям дескриптивного (описательного) типа. Они не являются предписывающими или нормативными.
А.В. Кирилина выделяет две тенденции лексикографического описания – создание системно-ориентированных словарей, отражающих целиком лексико-семантическую систему языка, и возникновение “антропоориентированных” словарей, репрезентирующих усредненный словарный запас и правила его использования отдельной языковой личностью, средним носителем языка, т.е. словари, обращенные к проблеме “человек в языке”. Первые имеют справочно-просветительские цели, а вторые – обучающие, направленные на активное овладение языком и поддержание знаний о нем (Кирилина 1993, с.10-11).
Основываясь на таком разграничении, ассоциативные словари смело можно отнести к антропоориентированным.
Ассоциативные словари могут иметь несколько входов: информация может быть упорядочена в зависимости от стимула (прямой словарь “от стимула к реакции”) и в зависимости от реакции (обратный словарь “от реакции к стимулу”). Например, английский ассоциативный тезаурус (АТНАЯ) или ассоциативный тезаурус современного русского языка (АТСРЯ) имеют по два входа.
В настоящее время опубликовано достаточно много ассоциативных словарей (несколько десятков). Некоторые ассоциативные словари создаются на материале внутриязыковых ассоциативных норм (и таких словарей большинство), но иногда словарь может включать и ассоциативные нормы, собранные на базе различных языков. К примеру, знаменитые “Нормы словесных ассоциаций” под редакцией Л. Постмана и Дж. Кеппела включают материалы на английском, немецком и французском языках (Postman 1970), а сейчас в секторе психолингвистики института языкознания РАН ведется работа по созданию ассоциативного тезауруса, включающего практически все славянские языки.
Первые ассоциативные нормы были собраны и опубликованы в 1910 году американскими психологами Г. Кент и А. Розановым. Они выбрали в качестве стимулов сто самых распространенных и общеизвестных слов (существительные, прилагательные и некоторые глаголы) и провели ассоциативные эксперименты с тысячью взрослых испытуемых, имеющих различные стратификационные данные по образовательному уровню, профессии, возрасту и полу (Kent, Rosanoff 1910). Таким образом, была собрана тысяча ответных реакций для каждого стимула. Потом продолжительное время изучалось в основном детское ассоциативное поведение и собирались нормы, полученные от детей и подростков. От взрослых же ассоциативные нормы во второй раз были собраны лишь через 40 лет. Это были так называемые “Полные Миннесотские нормы” (Russel, Jenkins 1952). Затем последовали “Коннектикутские нормы” (Bousfield 1953) и т.д. Во второй половине ХХ века появилась тенденция к сведению разнообразных ассоциативных норм воедино. Так, нормы Джироу и Поллио составлены на основе “Миннесотских” и “Коннектикутских” норм с добавлением их собственных данных, полученных от информантов университета штата Теннеси (Gerow, Pollio 1965).
Из всех существующих ассоциативных норм наиболее интересны, по мнению ряда ученых, “Нормы словесных ассоциаций” под редакцией Л. Постмана, куда включены почти все собранные ранее ассоциативные нормы на английском, французском и немецком языковом материале (Postman 1970). Список стимульных слов и количество информантов здесь практически не изменялось. После этого появились польские ассоциативные нормы (Kurcz 1967), болгарские (Герганов 1984), голландские (Made - van Bekkum 1973), украинские (Бутенко 1979), русские (САНРЯ 1977), латышские (Ульянов 1989), узбекские (Залевская 1971), киргизские (Титова 1975, Манликова 1989), казахские (Дмитрюк 1998). Значительно возросло количество двуязычных ассоциативных словарей. Так, исследование Л.Н. Титовой было проведено на базе казахского и русского языков, работа Н.В. Дмитрюк была выполнена на казахском и русском языке.
Стали появляться нормы, собранные на материале онтогенеза – словарь ассоциативных норм под редакцией Маршаловой на основе словацкого языка (Marsalova 1972). Т.М. Соколова составила ассоциативный тезаурус ребенка 3-5 лет на базе русского языка (Соколова 1996). Детские ассоциативные нормы собраны и описаны на различном возрастном онтогенетическом материале как в русском языке (Гасица 1990, Береснева 1977), так и на данных билингвизма (Салихова 1999).
Первый словарь ассоциативных норм русского языка был издан в 1977 году под редакцией А.А. Леонтьева (САНРЯ). Он был подготовлен на материале 500 слов - стимулов. Объем ассоциативных полей составлял от 150 до 650 слов-реакций, полученных на стимулы. Сам словарь, по выражению его составителей, имел “четко определенную практическую направленность на преподавание русского языка нерусским учащимся (в первую очередь иностранцам (САНРЯ, с.4))”.
Сейчас уже в 90-е годы этого столетия увидел свет уникальный ассоциативный тезаурус современного русского языка, который является словарем, принципиально отличающимся от первого как по своей структуре (словарь имеет два входа “прямой и обратный”), так и по качественному наполнению (значительно расширен список стимульных слов и несколько иной состав информантов). По выражению его составителей, этот тезаурус представляет собой “алгоритмически сконструированный лингвистический объект, являющийся одним из возможных способов представления языка” (АТСРЯ, т.I, с.6).
В последнее время в секторе психолингвистики института языкознания РАН собираются нормы восточных языков (вьетнамский, китайский) и редких языков народов Севера (бурятский, якутский, эвенский). Ведется и почти близка к завершению работа над проектом создания ассоциативного тезауруса славянских языков. По мнению Н.В. Уфимцевой, “Славянский ассоциативный словарь” является принципиально новым объектом лингвистического, этно- и психолингвистического исследования, позволяющий абсолютно по новому “взглянуть” на различие и сходства в славянском мире. Этому способствует единый список всех стимульных слов, включающий 112 единиц самой употребительной лексики и специальный подбор испытуемых. Участвовали 500 студентов и аспирантов различных университетов (14 специальностей) - мужчин и женщин поровну в возрасте от 17 до 25 лет. Данные собирались в 1998-1999 годах, т.е. в описываемом словаре будет содержаться “самая свежая” ассоциативная информация (Уфимцева 2000).
Чем удобны ассоциативные нормы? По мнению А.А. Леонтьева, во-первых, они дают результаты не избирательного, а массового эксперимента, что позволяет их использовать как источник уникальной лингвистической и паралингвистической информации. Во-вторых, ассоциативные нормы благодаря своей статистической “благонадежности” легко поддаются математической обработке, являясь уникальным материалом для выдвижения и проверки статистических гипотез. В-третьих, важно, что ассоциативные нормы дают в очень удобной форме специфический для данного языка и культуры “ассоциативный профиль” лексических единиц и помогают “выявить” ассоциативное значение слова (Леонтьев 1977, с. 10), они определяют тот стандарт, в котором отражены актуальные для сознания носителей языка особенности семантики слова - стимула. На основе ассоциативных норм исследуются как семантические, так и другие особенности слова, закономерности “работы” механизмов ассоциирования, типологии реакций.
Если провести определенную классификацию ассоциативных словарей, то на наш взгляд, ассоциативные словари могут быть описаны по таким параметрам:
Составление ассоциативного словаря (как и любого другого) – процесс крайне сложный и трудоемкий. Проанализировав несколько статьей и предисловий к ассоциативным словарям, мы пришли к выводу, что в среднем на составление словаря тратится около десяти лет. Такой временной срок может стать иногда проблемой при интерпретации и проверке на валидность ассоциативных данных, т.к. за этот промежуток времени (примерно десять лет) языковое сознание может существенно измениться даже при обычном развитии исторического процесса, не говоря уже об эпохе глобальных перемен. Например, ассоциативный материал для АТСРЯ стал накапливаться с 1988 года, а шестой и пятый тома АТСРЯ содержат данные, собранные уже в 1994-1995 годах. При специальной обработке данных (как качественной, так и количественной) вполне возможно проследить динамику языкового сознания на этапе перехода от одного социального строя к другому.
Построение словарной статьи в ассоциативном словаре, как правило, происходит так: словарная статья начинается со стимульного слова, затем идет ранговое упорядочение реакций по частоте и по алфавиту, и иногда приводятся количественные показатели ассоциативного поля. Например, словарная статья в АТСРЯ структурирована следующим способом: сначала идет стимул, а за ним слова – ассоциаты на этот стимул, расположенные по мере убывания их частоты, которая указывается в конце ряда одночастотных реакций. Реакции с одинаковой частотой упорядочиваются по алфавитному признаку. В конце каждой словарной статьи приводятся её количественные параметры: Бог ….92 + 61 + 3 + 46, где первая позиция показывает общее число реакций, вторая – число разных реакций, третья – число отказов от реагирования и четвертая – количество реакций с частотностью 1. Пересечение реакции со стимулами показано графически: реакции, совпадающие и несовпадающие со стимулами, выделяются различными шрифтами. По мнению авторов словаря, такое графическое представление информации помогает лучше отразить сетевые связи слов, отражающие их семантические, стилистические и ценностно-этические характеристики (АТСРЯ, т.1, с.6).
Структура словарной статьи обратного словаря построена по такому принципу: на первом месте идет реакция, выделенная жирным шрифтом, а на втором месте мелким шрифтом приводятся стимулы, её вызвавшие. Далее идут количественные показатели: на первом месте стоит показатель, указывающий на частоту данной реакции, т.е. на число испытуемых, ответивших данной реакцией на этот стимул. Затем после точки с запятой идут итоговые цифры, напечатанные курсивом и разделенные знаком “+”. Из этих двух цифр первая указывает на суммарное число появлений данной словоформы или словосочетания в качестве реакции на всем массиве стимулов, вторая обозначает общее число вызвавших эту реакцию стимулов, или, другими словами, число ассоциативных словарных статьей (в прямом словаре), где зафиксирована данная реакция. К примеру, содержание статьи в обратном словаре к слову “абсолютно”![]() может быть проинтерпретировано так: слово абсолютно в качестве ответа было дано семью испытуемыми на семь различных стимулов и может быть встречено в семи словарных статьях прямого словаря. Если испытуемые отвечали одним из слов, составляющих исходный список АТСРЯ, то такое слово выделялось с помощью “*” в обратном словнике: Губа* - нос, рот, увечье 1; 3 + 3 . Эта информация означает, что слова “губа” есть в списке стимульных слов, и в качестве реакции было зафиксировано по одному разу как реакция на слова “нос”, “рот”, “увечье”. При этом если реакция была зафиксирована лишь единожды на всем массиве стимулов, то указывающая на её единичность цифра “1” и итоговые цифры “1 + 1” авторами словаря пропускались: АБРИКОСОВАЯ – улица, АВОСЬКИ – переть. Если реакция была порождена только одним стимулом и с частотой больше единицы, то после стимула курсивом отмечалась только общая частота: АВТОМАТИЧЕСКИЙ – зонтик 4.
может быть проинтерпретировано так: слово абсолютно в качестве ответа было дано семью испытуемыми на семь различных стимулов и может быть встречено в семи словарных статьях прямого словаря. Если испытуемые отвечали одним из слов, составляющих исходный список АТСРЯ, то такое слово выделялось с помощью “*” в обратном словнике: Губа* - нос, рот, увечье 1; 3 + 3 . Эта информация означает, что слова “губа” есть в списке стимульных слов, и в качестве реакции было зафиксировано по одному разу как реакция на слова “нос”, “рот”, “увечье”. При этом если реакция была зафиксирована лишь единожды на всем массиве стимулов, то указывающая на её единичность цифра “1” и итоговые цифры “1 + 1” авторами словаря пропускались: АБРИКОСОВАЯ – улица, АВОСЬКИ – переть. Если реакция была порождена только одним стимулом и с частотой больше единицы, то после стимула курсивом отмечалась только общая частота: АВТОМАТИЧЕСКИЙ – зонтик 4.
Все реакции в обратном словаре упорядочены в зависимости от:
Рубрика “нет ответов” состояла из списка всех стимулов, на которые испытуемые не отреагировали хотя бы единожды. Внутри рубрики стимулы были упорядочены по частоте и по алфавиту и в конце приведено общее количество стимулов, вызвавших отказы от реагирования, и число разных стимулов по всей рубрике.
Словарная статья в САНРЯ выглядит несколько иначе. Её структура такова: после стимульного слова в скобках приводятся данные о частотности этого слова по словарям Джоссельсона (Josselson 1953) — условное сокращение Дж.; Штейнфельдт (Штейнфельдт 1963) — условное сокращение Ш.; Словарь Университета дружбы народов имени П. Лумумбы (2380 наиболее употребительных слов русской разговорной речи. M., 1968) — условное сокращение У. По Дж. даются: в числителе ранг (встречаемость, число порций текста, в которых встречено данное слово) и при нем в виде показателя степени - номер списка (напоминаем, что первый список в словаре Дж. был получен в результате иной процедуры, чем остальные, и данные по нему несопоставимы с остальными данными); в знаменателе—частотность. По Ш. даются: в числителе ранг, в знаменателе частотность. По У. дается только ранг (встречаемость). Например:
После скобок и тире приводятся все реакции в порядке убывания их частоты. Если количество ответов разными словами одинаково, они даются через запятую в алфавитном порядке. После основного текста статьи с новой строки идут параллели из английских (точнее, американских - А), немецких (G), французских (F), голландских (N), и польских (Р) ассоциативных норм. Приводится первый, наиболее частотный ответ; если давалось несколько ответов с равной или примерно равной частотностью, они приводятся через запятую, например: Arzt: Krankheit 38, Doktor 37. Поскольку исходные списки были не тождественны, то естественно не всегда приведены все параллели. Параллели даются примерно только для 100 слов из списка Кент - Розанова. Соответствующие этому списку русские слова помечаются звездочкой “*”. Крестиком “+” обозначены слова, данные по которым были уже ранее опубликованы. Статью завершает указание на число испытуемых (N =...).. (САНРЯ 1977, с.с. 67 – 68). Например, словарная статья на стимул “ребенок” выглядит таким образом:
Маленький 131, мальчик 41, взрослый 36, дитя 35, малыш 25, мать 23, мой 17, плачет 16, девочка, хороший 15, младенец 14, большой, малый, дети 9, капризный 8, сын, умный 7, плач 6, дочь, здоровый, кричит 5, мама, милый, пеленки, плакать, чай, человек 4, грудной, забавный, прелесть, радость, сестра, хорошенький 3, больной, Валя, детство, котенок, крик, парень, послушный, развитый, ребята, роддом, родной, смышленый, спокойный, ученик, чудесный, чудо, чужой, школа 2, Аленкина дочь, аппетитный, бабушка, балованный, баловник, бедный, белокурый, болеет, брат, брата, братик, веселый, вредный, глаза, голенький, головастик, голубоглазый, горький, да!, дед, детсад, Дима, Димка, “Дитте - дитя человеческое”, дорогой, дочка, драчливый, друга, дурак, жизнерадостная, золотой, игрушка, Ира, Иринка, их, к нему, кино, коляска, котлеты, которого выплеснули, красивый, кукла, лира, личико, люблю, маленький, миленький, Митька, молодой, муж, мяч, наш, непослушный, неспокойный, нет, новорожденный, один, озорной, опять, отец, парк, первый, пионер, писк, погремушка, ползет и плачет, потомок, прелестный, прийти, пухлый, радостный, ребенок, резвый, розовое, рыжий, Саша, светик, светлое, жизнерадостное, светлый, семья, серьезный, сестры, симпатичный, славный, слепой, совсем, спать, срочный, студенты, счастье, трудный, уехал, ученик, пионер, хилый, хорошо, хочу, цветы жизни, чепчик, что-то теплое, шаловливый 1. N==620.
А — baby: boy 162, child: baby (ies) 159, G — Baby:
Kind 66, Kind: klein 41, F — bebe: rose 25, enfant 23, enfant: petit 24, P - niemowie: dziecko 159, dziecko: male 286” (САНРЯ 1977, с.154).
Интересна и структура словарной статьи в двуязычном или полиязычном ассоциативном словаре. Например, в латышско-русском ассоциативном словаре она построена в сопоставительном плане (Ульянов 1988). Статьи расположены по алфавиту латышских слов-стимулов. Словарные статьи русских стимулов-эквивалентов приводятся непосредственно за словарной статьей соответствующего латышского стимула. Например: за стимулом сеls следуют дорога и путь, за duset — спать, дремать и дрыхнуть и т. д. Словарная статья синонима gи1ё1, следующая согласно алфавиту за словом dиset, снабжается сноской, в которой указывается, под каким номером помещены стимул duset и русские стимулы-эквиваленты спать, дремать, дрыхнуть (естественно, со своими словарными статьями). При этом приводятся и обратные ссылки. А сами статьи построены таким образом: в латышско - русской словарной статье за порядковым номером словарной статьи следуют слово-стимул и его перевод на русский язык (одним словом или, если необходимо, несколькими словами); общее число различных ответов на стимул; частотность слова-стимула по латышскому частотному словарю, число информантов, или общее количество ответов-реакций" (N== …). Начиная со второй строки, приводятся все слова-реакции (ассоциаты) в порядке убывания числа ответов данным словом: от самых частых до представленных двумя ответами (одиночные вербальные ассоциации по техническим причинам в данном словаре не приводятся); частота ассоциата указывается перед соответствующим ассоциатом (или рядом ассоциатов, имеющих одинаковую частоту); в ряду ассоциатов, имеющих одинаковую частоту, слова приводятся в алфавитном порядке (как в латышско-русской, так и в русской частях словаря); после латышского ассоциата дается его русский перевод, являющийся более или менее нейтральным, общим по значению словом (при полисемии или омонимии приводятся два слова), причем при выборе русского эквивалента к латышскому ассоциату прежде всего учитывается его ассоциативно-семантическая связь с исходным словом. Структура русской словарной статьи практически совпадает с латышско-русской. Частотность слова-стимула приводится по “Частотному словарю русского языка” (1977). Следует особо подчеркнуть, что такое представление данных в сопоставительном плане дает возможность не только уточнить значение конкретного слова в словаре, но и выяснить характер сходств и различий в лексике двух языков балто-славянской общности. Двуязычные словари со всей остротой выявляют и проблемы, связанные с переводом стимульных слов и его адекватностью (в формулировке подбора коррелятов слов в сопоставляемых языках в переводе А.А. Залевской (Залевская 1971)). Остро встает и проблема грамматических соответствий в сравниваемых нормах. Особо сложно, когда предъявляется список слов на неродном для информантов языке (Залевская 1971, 1979). В латышско-русском ассоциативном словаре приводятся подробные указания по поводу представления материала в сопоставительных ассоциативных полях (Ульянов 1989). Они ярко демонстрируют всю сложность задачи составления сопоставительных ассоциативных норм и оставляют открытыми ряд вопросов. Ю.Е. Ульянов снабжает словарные статьи такими комментариями:
“Регистрируются совпадающие стимул и реакция.
Если реакция в ответах информантов встречается в нескольких грамматических формах, то в качестве основного ассоциата приводится наиболее частая словоформа. При одинаковой частоте указывается только исходная форма (например, имя прилагательное указывается в именительном падеже единств венного числа, глагол — в инфинитиве и т. д.), остальные же варианты даются в круглых скобках в порядке убывания частоты, а если и эти показатели одинаковы, то по алфавиту.
В латышско-русских словарных статьях латышское словосочетание - ассоциат сопровождается русским переводом. Отсутствует такой перевод в том случае, если оба слова словосочетания приводятся в словарной статье в качестве самостоятельных ассоциатов.
Объединяются в один ассоциат и даются в скобках фонетические варианты слов (без вариаций лексического значения) или фонетико-морфологические варианты и т. д.
Как разные ассоциаты рассматриваются слова, в которых носителями языка осмысляются разные оттенки значения: “дочка - дочь, дом - домик, платье - платьице, коза - козёл, кот - кошка, человек – люди”.
Если возникают трудности при отнесении русского эквивалента к той или иной части речи (например, в случае конверсионной омонимии), то после русского перевода дается соответствующая помета: krasns (печь, печка),.silti тепло [кат. сост.].
Если непонятна актуализация слова – омонима в процессе ассоциирования, то в словарной статье даются оба перевода.
В латышско-русских словарных статьях были включены пометы, указывающие на стилистическую характеристику некоторых слов - ассоциатов. Появление последних во многом предопределено тем, что среди стимулов есть слова, относящиеся к разным стилям речи и имеющие разную стилевую и эмоциональную окраску. В силу того, что частотные показатели активности функционирования в речи разностилевых вербальных единиц представляют определенный интерес, то пометами были снабжены практически все разговорные, просторечные, книжно-поэтические и некоторые другие формы слов. Стилистические пометы даны по “Латышско-русскому словарю”. При русских эквивалентах и в русских словарных статьях такие пометы отсутствуют. Особые пометы даются к словам-терминам, характеризующим ту или иную область знаний, когда при переводе возникает затруднение в понимании значения слова.
Отдельно оговариваются указания и пояснения по частям речи.
Если в латышском языке имена существительные имеют только множественное число, а в русском — и единственное, и множественное, то русский перевод дается в единственном числе.
Имена собственные, за редким исключением, не переводятся.
Формы родительного падежа латышских имен существительных, употребленные в роли определения, переводятся на русский язык именами прилагательными, которые согласуются с русским стимулом-эквивалентом.
Русский эквивалент латышского ассоциата - прилагательного согласуется в роде, числе и падеже с русским переводом латышского стимула-существительного.
Некоторые латышские стимулы-существительные переводятся на русский язык двумя и более словами (это делается тогда, когда один русский эквивалент не исчерпывает значение латышского стимула). В этом случае русский эквивалент латышского ассоциата - прилагательного согласуется с первым словом перевода.
Русские прилагательные-эквиваленты латышских ассоциатов на стимулы-омонимы согласуются с теми русскими словами перевода, с которыми соотносятся по смыслу. Если же значение ассоциата в равной степени можно отнести к любому слову перевода, то в качестве русского эквивалента приводится имя прилагательное мужского рода единственного числа.
В русских словарных статьях имена прилагательные в полной и краткой форме объединены в один ассоциат.
Оценочные ассоциации (выраженные наречием или категорией состояния) приводятся отдельно от полных и кратких имен прилагательных.
Количественные числительные и порядковые прилагательные (числительные) приводятся в словарных статьях как разные ассоциаты.
Русский перевод латышских ассоциатов дается глаголами несовершенного вида.
Глаголы движения переводятся на русский язык в основном некратными глаголами линейного, целенаправленного действия.
Латышские глаголы должествовательного наклонения (vajadzibas izteiksme) не разграничиваются с основными глагольными формами. На русский язык перевод осуществляется описательно, а именно: модальное слово плюс инфинитив.
Объединяются в один ассоциат глаголы в разных грамматических формах, например словоформы видовые, темпоральные, модальные и т. д. с ярко выраженными формообразующими аффиксами. Рассматриваются как разные ассоциаты глаголы со словообразующими аффиксами, придающими слову новое лексическое значение (или иной оттенок значения), а также возвратные глаголы и глаголы с отрицательной частицей “не”: помнить — вспомнить, ожидать — | ожидаться, листать — перелистывать, учить — учиться — изучить, найти — не найти, durt — iedurt и т. д.
Причастия и деепричастия в русских словарных статьях рассматриваются как самостоятельные ассоциаты и не объединяются с глаголами, от которых они образованы.
В “русских” словарных статьях причастия в полной и краткой форме объединены в один ассоциат” (Ульянов 1989, с.с.36 – 40).
Приведенный перечень поясняющих инструкций демонстрирует всю сложность, возникающую при соотнесении стимулов – коррелятов и реакций – коррелятов. Здесь прослеживается и сильный субъективный момент, при интерпретации результатов САЭ – в целях формализации данных и чтобы добиться единообразия в их представлении, не все полученные реакции были отражены в ассоциативных нормах. Некоторые глагольные формы, краткие и полные формы прилагательных и причастий и многое другое рассматривались как одинаковые реакции, что, к сожалению, на наш взгляд, снижает внутреннюю валидность эксперимента и репрезентативность его данных. Мы считаем, что корректнее поступают авторы АТСРЯ, включившие в ассоциативные нормы даже рисунки, которые были даны в качестве реакций.
Отдельную проблему в ассоциативной лексикографии представляет отбор испытуемых в эксперименте. В основном ассоциативные нормы “отбираются” от студенческой аудитории, если перед экспериментатором не стоит специальная цель собрать данные онтогенеза. Считается, что к этому возрасту (17-21 год) формирование языковой способности уже в основном завершается. В свою очередь содержательное наполнение языковой способности (словарный запас, иерархическая структура ценностей, прагматические установки) и её формально-комбинаторные возможности у большинства людей остаются относительно стабильными на протяжении всей жизни (Караулов 1994, с.192-193). Это дает возможность изучать как бы несколько десятилетий ядро языкового сознания общества. При этом при собирании ассоциативных норм всегда важен также широкий территориальный и профессиональный “охват”. Однако мы полагаем, что проблема отбора контингента, т.е. тех людей, от которых собирались или предполагаются собираться нормы и влияние их языковой личности на эти нормы, ещё далека от своего окончательного решения. Проведенный анализ влияния некоторых социальных и биологических характеристик личности на её вербальное поведение показал, что некоторые факторы (половозрастная принадлежность информанта, условия его жизни, уровень образования и прочее) оказывают сильнейшее влияние, как на содержательное наполнение ассоциативных полей, так и на их структуру (Горошко 1997, 1998, 1999, 200)). К сожалению, при составлении норм большинство этих факторов практически игнорируется, что значительно снижает их репрезентативность (даже, когда объем ассоциативного поля и приближается к 1000 единиц).
Как самостоятельную проблему при составлении ассоциативных норм и словарей можно указать условия проведения эксперимента. И здесь сразу же возникает несколько вопросов, которые полезно оговорить отдельно.
Во-первых, крайне важна форма проведения эксперимента (устно или же письменно, групповое или индивидуальное предъявление списка стимульных слов).
Во-вторых, кем и как проводится эксперимент. Имеется в виду поведение экспериментатора, его индивидуальные характеристики, даваемая экспериментальная установка и прочее.
В-третьих, условия проведения – место проведение, погодные или иные условия, и т.д.
Все эти факторы являются практически неизученными. Нами не было найдено детального описания их влияния на ассоциативное поведение. Поэтому становится понятным, сколь важно то, как проводился САЭ. Как правило, ассоциативные нормы собираются в условиях группового письменного эксперимента. При собирании ассоциативных норм для АТСРЯ была использована анкета, состоящая из 100 стимульных слов, которые испытуемые должны были заполнить в течение довольно непродолжительного отрезка времени. Каждый стимул анкеты был снабжен определенным номером, и состав анкеты формировался на основе действия генератора случайных чисел, чтобы исключить появление одинаковых анкет. Таким образом, было максимально снижено влияние “ассоциативного стимульного окружения” на продуцируемые реакции (Черкасова 1996).
А вот ассоциативные нормы, вошедшие в САНРЯ, были отобраны “с голоса”. Экспериментатором зачитывался список стимульных слов, и испытуемых просили написать или первое, пришедшее в голову слово, или поставить прочерк, если ассоциации не возникало (САНРЯ, с.53).
Считается, что если мы хотим получить полноценные ассоциации, то объем списка стимульных слов должен не превышать 100 единиц. Если мы предъявляем больший список, то из-за возникающей усталости может исказиться истинная картина ассоциативного поведения информанта. Вследствие этого может увеличиться количество отказов, экстрасигнальных реакций и прочее. При сборе данных САЭ также важно, чтобы был грамотно проведен инструктаж, что тоже будет оговорено отдельно в соответствующей главе. Инструкции должны быть понятны испытуемым. А.А. Залевская заметила, что часто движимые “отвечать не как все” испытуемые пытаются давать не первую, пришедшую в голову ассоциацию, а записывать оригинальные идеи или “необычные”, чтобы избежать стереотипности ответов. Один испытуемый (юноша – киргиз) вписал, например, в анкету 35 личных имен. По его собственному признанию, он пытался сопротивляться своему стремлению давать стереотипные реакции (Залевская 1971, с.24).
Как в случае индивидуального, так и в случае массового эксперимента за один раз рекомендуется давать не более ста стимулов с одним или двумя перерывами по 10 - 20 минут.
В этом плане являются показательными эксперименты с детьми, где экспериментатор на время превращается или в партнера по игре, или в школьного учителя, который проводит очередное тестирование. И от квалификации экспериментатора напрямую будет зависеть результат эксперимента. Личный опыт автора работы свидетельствует, что всё же желательно, чтобы экспериментатор и интерпретатор исследования были одним физическим лицом, хотя бы в нескольких сериях экспериментов.
Кроме этапа собственно проведения САЭ, не менее важным при составлении ассоциативных словарей являются и две стадии, его сопровождающие или “окаймляющие”. Первая стадия – это формирование списка стимульных слов, а вторая – обработка результатов САЭ.
Список стимульных слов отбирается в соответствии тем задачам, которые словарь признан решить. В начале стимульными словами выступала высокочастотная лексика, т.е. слова, входящие в описание непосредственной жизнедеятельности человека. В первых ассоциативных нормах Кент – Розанова в качестве стимулов были отобраны общеупотребительные слова английского языка, в основном существительные и прилагательные. Долгое время этот список брался за основу при собирании норм на базе английского языка (Миннесотские, Коннектикутские нормы), или же переводился на другие языки при собирании на них норм (Rosenzweig 1961, Postman 1970). Со временем выявилась недостаточность этого списка, состоящего в основном из существительных в единственном числе и простых прилагательных. Первые усилия по расширению Кент – Розановского списка были сделаны Палермо и Дженкинсом в 1964 году. (Palermo, Jenkins 1964). Помимо традиционного списка они добавили 10 существительных во множественном числе, 10 переходных глаголов, 10 непереходных глаголов, три формы глагола “to be”, 3 причастия, 6 союзов, 2 междометия, 10 предлогов, 14 местоимений, 17 наречий и 15 дополнительных слов, из которых было 9 прилагательных в сравнительной степени, а 3 - артикли (Палермо 1966, с.254). А в ассоциативный тезаурус английского языка вошло уже 8400 слова, различающиеся по принадлежности к части речи и по грамматическим формам (Кish 1972, Залевская 1983). При подготовке первого этапа эксперимента была отобрана тысяча слов - стимулов - ЗОО слов из списка Палермо и Дженкинса и слова из первой тысячи наиболее частотных слов по частотному словарю английского языка 1944 года и из словаря “Бейзик Инглиш” (Ogden, I954). Все полученные на первом этапе реакции были использованы в качестве стимулов на следующем этапе. Таким образом, и было получено 8400 стимулов в окончательном списке.
Что касается русского языка, то для САНРЯ были отобраны в качестве стимулов 200 слов, исходя из частотного принципа (путем пересечения данных трех частотных словарей и недостающих слов из списка Кент – Розанова (САНРЯ, с.53, 61 – 66)). Для АТСРЯ исходный список стимульных слов был сформирован из 1277 слов, вошедших в САНРЯ, и дополнен выборочно словами из первой тысячи самых частых в текстах слов согласно “Частотному словарю русского языка” под редакцией Л.Н. Засориной (М., 1977). Затем он был расширен путем включения в него нескольких десятков слов - дескрипторов, отражающих жизненно важные или типичные для русской культуры понятия, из “Русского семантического словаря” под редакцией Бархударова (М., 1982).
Далее некоторые слова разных частей речи из этого списка авторы словаря решили “развернуть” в синонимические ряды (ложь, обман, вранье, враки, брехня; мука, мучение, терзание, пытка; большой, огромный, громадный; сочувствие, сострадание, соболезнование; гордый, заносчивый, спесивый, чванливый и т.п.), а также подобрать некоторым стимулам их антонимические пары (большой—маленький, умный—глупый), которые также были включены в состав стимулов.
Помимо этого для ряда слов из полученного состава стимулов была образована словоизменительная парадигма (воздух, воздуха, воздухом, воздуху, о воздухе; важный, важнее, важнейший; возьму, возьмешь, возьмет, возьмем, возьмете, возьмут; взял, взяла; я, ты, он, мы и т.д.), словоформы которой пополнили список. Были также образованы видовые пары для некоторых глаголов (рассказать - рассказывать, принести - приносить, бежать - бегать – убегать – убежать – сбежать и т.п.). Затем список был проверен на “охват” всех частей речи и дополнен некоторыми порядковыми и количественными числительными, местоимениями, частицами, междометиями и союзами. Таким путем был сформирован окончательный состав стимулов. В итоге в Русском ассоциативном словаре (в прямой и обратной его частях) представлено более 1 миллиона словоупотреблений, 52 тысяч разных словоформ и около 12,5 тысяч разных лексических единиц (АТСРЯ, т.1, с. 192).
Существуют и уникальные ассоциативные словари, где списки стимульных слова отбирались с учетом исследовательской задачи. Так, в 1989 году появился ассоциативный словарь русской этнокультуроведческой лексики (Манликова 1989). Своеобразие этого словаря состоит в том, что его исходной базой послужила лексика, не нейтральная и наиболее частотная, а отмеченная повышенной национально – культурной характерностью, репрезентирующая систему знаний о специфической культуре русского народа как историко-этнической общности (Манликова 1989, с.9). Лексика была отобрана из произведений русской литературы. В список стимульных слов вошли этнографизмы - русизмы (армяк, алтын, горница, крыльцо, няня, щи, ямщик), историзмы - русизмы (барин, городничий, государь), историзмы - интернационализмы (граф, гувернер, карета, лакей), бытовые регионализмы, иностранные общеязыковые заимствования, локализмы (вист, акын, сакля, улан), религиозная лексика (демон, икона церковь, поп), натурализмы (крещенский). Были введены и так называемые фоново-коннотативные слова: книжные поэтизмы и “высокая”, торжественно - риторически окрашенная лексика (дева, отечество), фольклоризмы (девица, молодец, тридевятый), общеязыковые и локально - исторические литературные символы (буря, кнут, топор, ярем, ярмо), оценочные слова - характеристики (недруг, подлец, хрыч, сторонушка, судьбина), этикетные слова - официальные обращения и их компоненты (благородие, милость, сударь), ласкательно-почтительные и фамильярно-просторечные обращения (батюшка, матушка, братец, голубушка) ономастическая лексика, в частности антропонимы (Палашка, Савельич) (Манликова 1989, с.16-17). Интересно и то, что ассоциативные нормы на эти стимулы были отобраны как от русских, так и от киргизов, учащихся национальных слов. Этот уникальный эксперимент, помимо научных целей преследовал и чисто практическую - выявление фоновых знаний учащихся – киргизов о русской культуре.
Инновационный и нетривиальный подход к формированию списка стимульных слов был предпринят авторами готовящейся к печати работы “Ассоциации информационных технологий: эксперимент на русском и французском языке” (Дельфт, Филлипович, Черкасова 2001). Для составления двуязычного ассоциативного словаря в области информационных технологий и компьютеров был взят корпус статей различных авторов из годовой подборки журнала Компьютер Вик за 1995 год. Всего было выбрана 31 предметная область, начиная от рынка программных средств и заканчивая рынками программ и программистов. С помощью компьютерной программы Диалекс был составлен алфавитно-частотный словник по выбранной предметной области. Затем русские слова были приведены в свои исходные формы (глаголы – в форму инфинитива, существительные в единственное число, именительный падеж и прочее) и упорядочены по степени убывания частоты и алфавиту. После этого были удалены общеупотребительные слова, персоналии и имена собственные, а также графические формы слов на латинице. Полученные слова были отсортированы на два списка, предъявляемых отдельно профессионалам в данной предметной области и нет. К сожалению, авторы подробно не описывают, на основании каких критериев отбирались слова для профессионалов и непрофессионалов. На базе первых двух списков был сформирован и переведен на французский список стимульных слов, предназначенный для франкоговорящих “непрофессионалов” (Черкасова 2000). По приведенным в работе основным характеристикам специализированного ассоциативного списка видно, что авторы включили полные синонимические ряды слов (диск, винчестер, гибкий диск) и целые понятийные группы (программа, программирование, программист и язык программирования). Авторы считают, что сравнение и сопоставление ассоциативных полей, полученных от такого стимульного списка, позволило бы учесть всю специфику ассоциаций в исследуемой предметной области (Черкасова 2000, с.272).
Ещё одна проблема, возникающая при составлении ассоциативных словарей, связана с обработкой результатов проведения САЭ. Вначале все данные обрабатывались вручную. Однако с появлением и распространением компьютерной техники, т.е. с начала 70 годов, появилась и электронная обработка данных, а затем и создание электронных версий словарей (компьютерный вариант АТСРЯ) и даже размещение их на сайтах Интернета (Черкасова 1996, 1998). Например, ассоциативный тезаурус английского языка “весит” в Интернете с 1998 года.
Как правило, первичный отбор анкет осуществляется по “горячим следам”, сразу же после проведения эксперимента. Анкеты, в которых содержится более 30% пропусков, отбраковываются экспериментатором. Отбраковываются также и анкеты, в которых, по выражению Ю.Н. Караулова, испытуемый разрушает модель квазидиалога с экспериментатором (Караулов 1996, с.68) и отвечает не на предложенные ему стимулы, а на какие-то свои собственные, никак с предложенными не связанными. Когда количество таких реакций составляет более 50%, анкета из эксперимента исключается. При собирании норм АТСРЯ таких анкет встретилось примерно 20% (Там же). В указанной работе Ю.Н. Караулова приводится и пример отклоненной анкеты, когда испытуемый просто не захотел участвовать в эксперименте:
| 6649 | умно | чего |
| 4672 | жлоб | вы |
| 4677 | За бугор | от нас |
| 4436 | городить | хотите |
| 6347 | советским | дорогие товарищи |
| 4709 | зажигать | и |
| 3991 | акцент | зачем |
| 6647 | сук | вам |
| 4876 | канава | все это |
| 5751 | подлый | нужно |
(Там же, с.69).
Некоторые составители словарей неразборчивые или бросающиеся в глаза однотипные ответы, шуточные и прочие также не включали в экспериментальные данные (Ульянов 1988, с.34). Если испытуемыми были замечены в том, что они работаю больше положенного срока или же списывают ответы, то их анкеты также изымались из эксперимента. После первого отборочного этапа наступает формирование банка ассоциатов и создание собственно ассоциативных норм, т.е. ввод информации в компьютер и дальнейшая уже компьютерная обработка.
Одним из первых ассоциативных словарей, существующих в электронном виде, стал ассоциативный тезаурус английского языка под редакцией Дж. Киша (Кish 1972). Словарь появился в Великобритании. В качестве информантов была избрана многопрофильная студенческая аудитория. Одно из условий проведения эксперимента - каждый испытуемый мог только один раз в нем участвовать. Эксперимент проходил письменно в группах по сто человек. Сразу предъявлялось каждому участнику по 100 стимульных слов.
Подготовка словаря и проведение эксперимента состояла из нескольких этапов, причем реакции, полученные на первом этапе, использовались в качестве стимулов на втором и т.д., т.е. количество стимулов увеличивалось в геометрической прогрессии, и по достижении 8400 стимульных слов эксперимент был остановлен. К этому времени был собран банк реакций, состоящий из 55 800 единиц.
Теоретической основой словаря послужила концепция Дж. Киша, который трактует лексикон человека как систему поиска информации, управляемой вероятностными процессами. При поступлении запроса в эту систему, предлагается ряд ответов, которые различаются по степени их соответствия запросу. Вероятность выбора определенного слова рассматривается Кишем как функция уровня его активности в текущий момент. Чем выше уровень активности, тем вероятнее слово будет выбрано для дальнейшей работы и попадет на табло сознания. Уровень активности отдельного слова зависит от состояния системы, и от переходов этой системы из одного состояния в другое. Общий уровень активности системы в среднем не изменяется, а относительное повышение уровня активности отдельного слова может происходить только за счет активности других слов. Общая же сумма показателей уровня активности всех слов не должна превышать некоторую константу, которая четко фиксируется.
Разрабатывая математическую модель своей гипотезы о строении лексикона, Дж. Киш использовал теорию графов, которая, по его мнению, позволила учесть, как вероятностную природу системы, так и особенности внутренней организации лексикона. Дж. Киш представил все ассоциативные связи слов в виде графов, упорядочив всю числовую информацию по ним (количество ребер, вершин и прочее), исходя из матричного принципа. Сумма по строкам соответствовала “ценности” (весу) исходящих связей, а сумма столбцов свидетельствовала о ценности входящих связей. Так, при равном количестве связей, их вес мог значительно различаться. Применение таких матриц позволило Кишу сделать ряд интересных выводов по поводу организации внутреннего лексикона человека, а главное обеспечило уже в начале 70-ых их компьютерную обработку. Структурный компьютерный анализ корпуса тезауруса позволил получать автоматически ассоциативное окружение каждого слова с заданным числом шагов (переходов) в виде распечатанной дендрограммы.
Сам ассоциативный тезаурус состоит из двух частей. В первой части содержится информация об исходящих и входящих ассоциативных связях для 8400 стимульных слов. Во второй части, которую Киш окрестил как “Остаток”, содержатся данные о входящих связях слов, которые не были использованы в качестве стимульного материала и указывается, какие слова и с какой частотой вызвали эти слова в качестве реакций. Интересно, что при составлении словаря была сохранена оригинальная орфография информантов и никакие грамматические ошибки в написании ассоциаций не исправлялись. Не объединялись и вариативные формы ассоциаций, в отличие, например, от латышско – русского ассоциативного словаря (Ульянов 1989). В конце каждой ассоциативной статьи приводятся показатели частоты прямых и обратных связей, количества разных реакций на стимул и количество разных стимулов, вызвавших одинаковую ассоциацию. Первопроходческий характер работы Киша заключался в том, что впервые основываясь на принципе “обратного” анализа ассоциативных данных, стал возможным ответ на вопрос “Если есть некоторое слово, то какие слова могут вызвать его в качестве реакций в САЭ?” До этого по ассоциативным нормам можно было сделать выводы только о том, какие реакции может вызвать данный стимул.
Дж. Киш полагал, что словесные ассоциации выступают как показатели степени связанности между понятиями, доступ к которым осуществляется через их значения. Ассоциативные нормы и ассоциативная сеть дает прямое картирование этого аспекта наших знаний (Залевская 1983, с.37). Отсюда следует вывод, что ассоциативные нормы являются крайне важным индикатором структуры языкового сознания. Они не только показывают, какие его элементы являются смежными, но и указывают на степень связи и согласованности между его элементами. В дальнейшем многие теоретические взгляды Киша на организацию лексикона человека были развиты (и зачастую в прикладном аспекте) в работах тверской психолингвистической школы в области организации лексикона человека, разграничении антонимии и синонимии, сложного слова и словосочетания в английском языке, степени актуальности определенного ЛСВ для современного этапа развития языка и многих других проблем, которые были неподвластны традиционным лингвистическим методам (Залевская 1983, с.37-39).
Идеи компьютерной обработки ассоциативного материала воплотились и при создании АТСРЯ, наиболее представительного из всех, имеющихся в наличие ассоциативных словарей. Можно предположить, что создание АТСРЯ явилось неким аналогом ассоциативного тезауруса английского языка, и было продиктовано в частности задачами межъязыкового сопоставления, облегчающими решение проблем соотношения и взаимодействия языковых и энциклопедических знаний и их организации в процессах коммуникации и речемыслительной деятельности.
Исходные данные АТСРЯ были получены в результате трехэтапного анкетного опроса испытуемых в ходе массового ассоциативного эксперимента, проводимого с 1987 по 1997 годы. Первый этап практически ничем не отличался от построения традиционных ассоциативных словарей, за исключением того, что стимульный список слов был значительно расширен. На втором этапе в качестве стимулов использовались реакции первого этапа эксперимента. Третий этап явился повторением второго этапа с использованием реакций этого этапа в качестве стимулов для новой выборки испытуемых, т.к. “ассоциативное семантическое пространство”, после третьего этапа как бы замыкается, т.к. не происходит добавления новых слов и смыслов в реакциях (АТСРЯ, т.I, с.5). Всего было выпущено 6 томов АТСРЯ. Последний том вышел в 1998 году.
Каждый этап эксперимента включал такие шаги:
Компьютерная технология создания АТСРЯ довольно проста. Её можно изобразить в виде системы, состоящей из программной оболочки и баз данных.
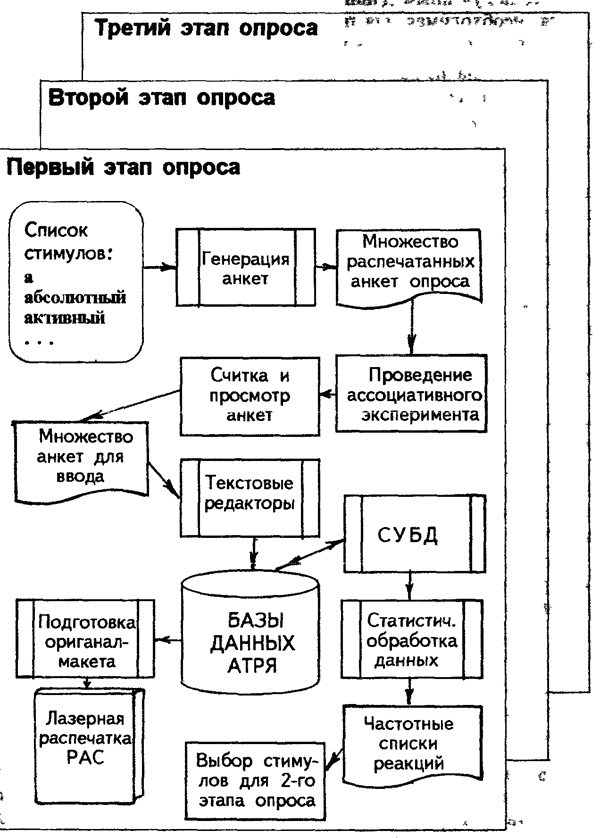
(Приведено по Черкасовой 1996, с.186)
Количественные характеристики компьютерной версии тезауруса могут быть представлены в виде такой таблицы:
| Номер этапа | Число стимулов | Количество ассоциативных пар | Количество различных пар | Количество различных реакций | Прирост числа реакций |
| I | 1277 | 451 373 | 171753 | 52177 | 52177 |
| II | 2685 | 281 246 | 152874 | 50872 | 30162 |
| III | 2935 | 304 900 | 245433 | 47027 | 21996 |
| Всего | 6624 (т.к. некоторые стимулы повторялись) | 1 037519 | 470033 | 150076 | 104335 |
(Черкасова 1998, с.130)
В компьютерную версию АТСРЯ входят 7 баз данных: 4 основные (база стимулов ассоциативного эксперимента, основная (исходная) база данных, базы данных прямого и обратного ассоциативных словарей) и 3 вспомогательные базы (база анкетных данных информантов, база специальностей информантов и база населенных пунктов, в которых происходил эксперимент).
С помощью компьютерной версии тезауруса могут решаться следующие исследовательские задачи:
· Формирование различных выборок;
· Построение проекций прямого и обратного словарей;
· Получение упорядоченных списков;
· Создание лемматизированного индекса (Черкасова 1998, с.130).
Перед исследователями стояла задача всестороннего изучения множества понятий, которые охватывает тезаурус? и требовалось оценить мощность этого множества. В связи с этим была произведена лемматизация множества всех словоформ, хранящихся в базах данных. За “отправную точку” были взяты списки заголовочных слов и словосочетаний из всех 6 томов АТСРЯ. Для каждой леммы “вычислялся” с помощью специально разработанной компьютерной программы соответствующий номер тома и страница. Это позволило, по мнению одного из авторов словаря, препарировать информацию не только потомно, но и получить обобщенные характеристики и выделить множество понятий АВС, определить направленность и обозначить систему связей между понятиями (Черкасова 1998, с.131). Предполагается, что лемматизированные индексы составят содержание 7 тома тезауруса.
Уникальные исследовательские задачи, которые могут решаться при помощи электронной версии тезауруса, связаны с формирование различных выборок, проекций и списков, отвечающих определенным формальным критерием, информация о которых содержится в электронных базах данных. Например, одна из таких задач - формирование “мужского” и “женского” списка ассоциаций, по которым можно будет проследить влияние гендерного фактора на ассоциативное поведение испытуемых, или с “введение” параметра “профессиональной ориентации” можно сравнить предполагаемые ассоциативные миры русского гуманитария и инженера.
Следует заметить, что одним из несомненных достоинств электронной версии АТСРЯ является его постоянная динамичность. Современный словарь – это не застывшее образование. В отличие от его печатной версии он постоянно может пополняться и изменяться, т.е. он может существовать как в статике, так и в динамике.
А теперь постараемся ответить на вопрос “Для чего же нужен такой ассоциативный словарь и кто может стать его предполагаемыми пользователями?”. На наш взгляд, чтобы правильно ответить на поставленный вопрос, необходимо четко сформулировать для себя “что являет собой собственно ассоциативный словарь и какой фрагмент человеческого знания он представляет?”.
Теоретической основой тезауруса стало психологическое представление о том, “что явления реальной действительности, воспринимаемые человеком в структуре деятельности и общения, отображаются в его сознании таким образом, что это отображение фиксирует причинные, временные, пространственные связи явлений и эмоций, вызываемых восприятием этих явлений (АТСРЯ, т.I, с.7)”. Это слепок “усредненной” человеческой ментальности, модель человеческого сознания.
А.А. Леонтьев ещё в предисловии к первому ассоциативному словарю русского языка писал, что “если нам нужно найти метод, с наибольшей объективность позволяющий вскрыть “культурную” специфику словарных единиц, вскрыть те побочные, непосредственно не релевантные для обобщения семантические связи, которые имеет данное слово, его семантические “обертоны”, - без сомнения, таким методом является ассоциативный эксперимент, а ближайшим источником данных на этот счет – словарь ассоциативных норм” (Леонтьев 1977, с.14).
По выражению Н.В. Уфимцевой, ассоциативный словарь является и отражением вербальной памяти человека и фрагментом образа мира того или иного этноса, отраженного в сознании “среднего” носителя той или иной культуры, его мотивов и оценок и, следовательно, его культурных стереотипов. С помощью тезауруса мы получаем, прежде всего, возможность определить “круг понятий, наиболее важный для современного русского языкового сознания, т.е. для образа мира современных русских” (Уфимцева 1996, с.141).
По существу ассоциативные поля, образующие корпус такого словаря, можно рассматривать “как обозначение культурно заданных границ понятия, в пределах которого оперирует индивидуальное сознание говорящего” (Караулов 1994, с.262). Анализируя обобщенные ассоциативные поля и поле, полученное от отдельного индивида, мы можем судить о содержании каждого индивидуального сознания. Более того, если ассоциативное поле есть отображение языкового сознания носителя языка, то оно может, следовательно, более непосредственно указывать на форму и способы хранения образов языкового сознания (Там же). Т.е. данный словарь дает нам своего рода систему интуитивных представлений о реальности, об окружающем нас мире. Н.В. Уфимцева полагает, что принципиальное отличие ассоциативного тезауруса от традиционных лингвистических словарей и его принципиальная ценность, это то, что словари, которые составляются филологами, как правило, являются описанием “индивидуального лингвистического” языкового сознания, в то время как тезаурус является “одним из возможных способов описания “коллективного обыденного” языкового сознания реальных носителей языка и, следовательно, более адекватно отображает реальное языковое сознание в его усредненном состоянии (Уфимцева 1998, с.с. 76 - 77). Тем самым он приближает нас к “ассоциативному” пониманию проблемы личного и коллективного бессознательного, а также архетипа в формулировке К. Юнга (Шульц Д.П., Шульц С.Э. 1998, с.441 – 443).
Материалы тезауруса можно рассматривать, по выражению Н.В. Уфимцевой, и как совокупность “указателей” на глубинные механизмы вербального и невербального поведения в процессе порождения речевого высказывания (Уфимцева 1998, с.76).
Сами авторы тезауруса в предисловии к первому тому, так обозначили его “словарную нишу”:
во-первых, принципиально новый источник изучения языка и феномена владения языком,
во-вторых, база для анализа путей формирования языкового сознания в онто – и филогенезе, формирования методологических и теоретических схем анализа языкового сознания,
в-третьих, мощный инструмент и “специфическое” справочное пособие для обучения русскому как родному, так и иностранному, а также средство оптимизации процессов речевого общения при межкультуроной и интеркультурной коммуникации (АТСРЯ, т.I, с.5).
Во вступительном слове к пятому тому АТСРЯ, подводящему итог многолетних усилий большого авторского коллектива, Ю.Н. Караулов подчеркивает, что предлагаемый словарь отвечает двум требованиям, которые необходимы для того, чтобы словарь “имел статус” тезауруса. Он должен охватывать всю лексику языка и в явном виде фиксировать некоторые отношения между составляющими его единицами (АТСРЯ, т.Y, с.5). Под понятием “вся лексика” Ю.Н. Караулов подразумевает всю лексику, “охваченную современными ассоциациями, включаемую носителями в широкую сеть ассоциативных отношений” (Там же).
Говоря иначе, составители АТСРЯ рассматривают его “как модель речевых знаний носителей языка, представленных в виде АВС, позволяющей объяснить феномен владения языком и служащей – наряду с текстовым и системным – способом представления русского языка” (АТСРЯ, т.I, с.6). АВС – это новый способ репрезентации языка, объединяющий его текстовую и системную формы (Там же). В АВС, например, может содержаться информация о значении полисемантического слова, его синонимических и антонимических рядах, синтаксической сочетаемости, словоизменительной и словообразовательной варьируемости, а общая степень грамматикализации слов сети совпадает со степенью грамматикализации (соотношение грамматически оформленных и нулевых форм) русского текста (Там же).
АВС можно рассматривать также как определенную совокупность знаний речевого коллектива, складывающуюся из суммы знаний его носителей. Эти знания условно подразделяется Ю.Н. Карауловым на три вида:
· Внеязыковые, или экстралингвистические знания, воссоздающие мозаичную картину мира усредненного носителя языка;
· Диалоговые знания, отражающие языковое сознание носителей и содержащие элементы рефлексии по поводу языка, культуры, т.к. в реакциях часто содержится оценка понятиям, событиям и типовым ситуациям русской действительности, т.е. проявления языкового сознания в АВС;
· Интуитивные знания носителей языка, касательно устройства самого языка, его поуровневой структуры, т.е. отражение грамматического строя и словарного состава языка (Караулов 1994б, с. 194-212).
Исходя из вышесказанного, становится понятным, что материалы тезауруса могут быть использованы в гуманитарном знании (философия, культурология, право, социология, психология, лингвистика), так и при решении ряда прикладных задач в психиатрии, психодиагностике, криминалистике, рекламе или же в совсем недавно возникшем спичмейкерстве.
Итак, кому может быть полезен такой словарь?
Прежде всего, тем, кому интересны вопросы, связанные с исследованием особенностей русского менталитета. Так, философ или же культуролог может попытаться, исходя из анализа ассоциативных полей, определить и проследить развитие элементов, входящих в “наивную картину мира” русского человека, выявить структуру этой картины. Например, мы можем увидеть, прочитав статью на слова “работа”, что она, прежде всего, “не волк” (и, следовательно, в лес не убежит), а деньги для русского человека могут быть большими, бешеными и шальными, они приносят зло и грязь, но они нужны и они не пахнут![]() . А что могут делать русские с деньгами? Сначала тратить, затем платить и считать, но отнюдь их не зарабатывать (Уфимцева 1996).
. А что могут делать русские с деньгами? Сначала тратить, затем платить и считать, но отнюдь их не зарабатывать (Уфимцева 1996).
Для социолога и культуролога, изучающих проблемы проникновения культурных феноменов в обыденное сознание носителей русского языка, подобный словарь является как бы широкомасштабным социологическим опросником. Он позволяет, например, “восстанавливать мозаичную картину распределения знаний классического и массового искусства”, и на этой основе понять восприятие и отношение русских к явлениям своей культуры или же какой-либо из субкультур (Караулов 1994, с.214). По мнению А.А. Залевской, ассоциативный материал создает основу для межкультурных и междисциплинарных исследований, помогая выявить как “общечеловеческие” характеристики свободных ассоциаций, так и ту неповторимость, которую им придает та или иная культура (Залевская 1978). Так, для носителей русского языка по данным тезауруса наиболее частотные реакции на слово “друг” - верный, враг, детства, мой, товарищ и лучший. У англичан же на стимул “friend” (англ. друг) самая частотная реакция - это враг и противник, затем следуют слова девушка и хороший (Уфимцева 1996).
Мы думаем, что данные такого словаря могут быть полезны политологам и социологам для анализа системы аксиологических образцов и иерархии ценностей, а значит и характерных для определенного общества убеждений, идеалов, склонностей, интересов и других социальных установок, отличающих данную общность от другой. Известно, что в критические периоды развития общества (а именно в такой период и формировался весь корпус словаря) наиболее ярко проявляются некоторые психолингвистические особенности слова. Так, в обиход входят новые слова с отставанием в формировании соответствующих понятий, а некоторые из имевшихся ранее слов в той или иной мере переосмысливаются или вызывают иные эмоционально-оценочные переживания и образы, что существенно повышает информативную ценность такого словаря как для лингвистов, так и для всех специалистов, изучающим ментальность россиян (Ментальность россиян 1997, с.38). Например, в условиях зарождающихся рыночных отношений для предполагаемых инвесторов в экономику России было бы интересно узнать, что у русских слово бизнесмен ассоциируется прежде всего со спекулянтом, дельцом, вором, бездельником и пронырливым человеком, делающим деньги из воздуха.
Ассоциации дают уникальную возможность заглянуть в мир эмоций и представлений, с ними связанных, и посмотреть, как эмоции репрезентируются в мышлении человека и как соотносятся с национально-культурной спецификой его восприятия мира. Например, у русских гнев ассоциируется прежде всего с яростью и злостью, он праведный и сильный, и, что наиболее удивительно, следующее с чем он связан это слова радость и милость. А вот у англичан самой частотной реакцией на гнев стало слово отвращение, а затем жалость (Уфимцева 1996). Благодаря ассоциативным нормам, мы можем “посмотреть” на место эмоций в структуре языкового сознания, т.к. до сих пор многие проблемы, связанные с эмоциями и со спецификой “эмоциональной картины мира”, продолжают в значительной степени оставаться тайной (Мягкова 1996, с.176). Автора данной работы материалы словаря подтолкнули к проведению лонгитюдного исследования и составлению словника, содержащего ассоциативные нормы для большого ряда слов, описывающих эмоции и эмоциональные состояния в русском языке (Горошко 1999, 2001).
На анализе языковых норм для разных языков и взаимного соответствия семантических и ассоциативных свойств языковой единицы основаны исследования структуры памяти и внутреннего лексикона - множества номинаций, упорядочивающих знания человека о мире. Это направление особенно актуально, поскольку позволяет изучать особенности языкового мышления, а также и моделировать искусственный интеллект. По мнению ряда исследователей, проблема ассоциаций, их классификации и механизмов ассоциирования напрямую связана с изучением хранения знаний о мире и устройства памяти человека (Залевская 1999).
Для психологов и психиатров данные тезауруса помогут оценить материалы САЭ, отбираемые в условиях патологии или же измененных состояний сознания, позволяя судить о степени и характере различий, “индуцируемых” патологией, а также дать определенную диагностическую информацию об этой патологии. Для психодиагностики также крайне интересны и ассоциативные поля, собранные в словаре на цветонаименования и цветовые реакции: какие стимулы их вызывают, состав реакций и их эмоциональная окраска, частотные показатели, предпочтительные цвета, сравнение предпочтительности цветов в тезаурусе с данными проективной методики М. Люшера (Бурлачук, Морозов 1989). В самостоятельную исследовательскую проблему может быть выделена задача - установить, какое символическое значение приписывается каждому цвету в языковом сознании его носителей. Интересно изучить и сравнить структуры пространства цветов и эмоций, и с этой точки зрения попытаться проверить их изоморфизм (Яньшин 1996). Нами были собраны и проанализированы ассоциативные нормы на 11 фокальных цветов и цветонаименований в русском языке (Горошко 2000). Не имея возможности в пределах одной работы, затронуть все особенности цветового видения мира носителями русского языка, мы все же смогли четко проследить, с чем связан в русском языке тот или иной цвет, а также в какой-то мере судить и о национальной (русской) цветовой символизации. Основываясь на собранных нормах и проведя их качественный и количественный анализ, мы ясно увидели, что особенностью цветовой семантики является её многозначность. Каждый цвет характеризуется системой устоявшихся и ассоциативно возникающих смысловых значений: от индивидуально-специфических до универсальных. Семантические значения цветов являются многоуровневыми, включают предметные, эмоционально-оценочные, метафорические и другие ассоциации. Кроме того, на основе ассоциативных “цветовых” норм возможно формализовать результаты и установить меру близости цветов в семантическом пространстве. Нормы также показали, что существуют определенные зависимости между ассоциативными полями цветов и цветонаименований и различными биосоциальными характеристиками личности человека. Мы установили влияние гендерного и стрессового фактора, а также “специальных” условий жизни (длительной изоляции от общества) на особенности проявления ассоциативное поведение информантов. Данные норм подтвердили и гипотезу о существовании сильных и достаточно однозначных связей между цветами и эмоциональными состояниями, которые, по всей видимости, принадлежат к глубокому и невербальному по своей природе уровню эмоциональных значений.
Материалы АТСРЯ могут быть использованы и в рекламном бизнесе, а также в работе спичмейкеров, т.е. людей, профессионально занимающихся воздействием слова на массовое сознание. Для них такой словарь - это своего рода справочник, предоставляющий ценнейшую информацию о том, с чем более всего ассоциируется слово в сознании человека, а, следовательно, на этой информации можно “сфокусировать” коммуникативную задачу, решаемую рекламным текстом, и судить об эффективности воздействия рекламного текста на народонаселение. Для специалистов в области “пиарных” технологий – спичрайтеров и спиндокторов – при решении профессиональных коммуникативных задач также будет не бесполезна информация, собранная в массовых ассоциативных экспериментах. Для этих же “нужд” словарь может быть востребован и мастерами пера: писателями, поэтами, переводчиками. Каждая статья словаря, будучи “языковым зеркалом среднего носителя языка”, дает бесценный материал всего того, что стоит в обыденном сознании человека за словом. Все разнообразие ономастикона, надписи, лозунги, реклама и метафора, фрагменты вербального научного и культурного знания, все индивидуальное или же, наоборот, банальное может почерпнуть человек, работающий со словом профессионально (Караулов 1994б). И естественно он сможет использовать это знание о слове то ли для того, чтобы передать точнее речь какого-либо персонажа своего произведения, или подыскать нужную рифму в стихе, а может быть и чтобы “вычеркнуть” ненужные слова из предвыборных речей наших политических деятелей. А, возможно, что словарь станет для кого – то попросту источником вдохновения, и в этом реализуется одно из его главных предназначений.
Интересен и опыт использования такого словаря в криминалистике, при проведении судебно - автороведческих и фоноскопических экспертиз. Имеется в виду возможность проведения сопоставительного анализа ассоциативных полей словаря с индивидуальным ассоциативным словарем лиц, причастных к составлению того или иного документа. При проведении диагностических судебно - автороведческих исследований текста часто работниками правоохранительных органов ставится задача создания социально-биографического портрета автора анонимного документа (т.е. по тексту длиной 80 - 150 слов требуется определить возраст, пол, уровень образования, место формирования речевых навыков, иногда профессиональную принадлежность лица, причастного к созданию этого текста, его необычное психофизиологическое состояние и т.д.). А исходя из того, что словарь имеет компьютерную версию и составлен на основании анкет, содержащих информацию о половой принадлежности испытуемых, возрасте, будущей профессии, а также сейчас собираются ассоциативные нормы на территории бывших республик СССР, позволяющие судить о месте формирования языковых навыков (например, ассоциативные нормы, собранные в ходе массового ассоциативного эксперимента на Слобожанщине![]() ), то становится реальной возможность выявление всей специфики реакций, обусловленной различиями в перечисленных параметрах. Более того, крайне интересной и немало важной представляется задача расширения анкетных сведений о биографических данных испытуемых с целью описания особенностей их ассоциативного поведения и структуры ассоциативных полей в зависимости от той или иной составляющей социально - биографического портрета. Разграничение ассоциаций в зависимости от пола испытуемых и сравнение их с общими “смешанными” нормами из тезауруса способствовало доказательству гипотезы о существовании полового диморфизма в речевой деятельности русскоязычных коммуникантов и помогло выявлению и описанию особенностей мужского и женского вербального поведения (Горошко 1996). Показав, что половому диморфизму подвержена собственно языковая способность человека (в частности вербальное ассоциативное поведение), мы как бы априори смогли доказать его предполагаемое влияние гендерного фактора на все уровни языковой структуры.
), то становится реальной возможность выявление всей специфики реакций, обусловленной различиями в перечисленных параметрах. Более того, крайне интересной и немало важной представляется задача расширения анкетных сведений о биографических данных испытуемых с целью описания особенностей их ассоциативного поведения и структуры ассоциативных полей в зависимости от той или иной составляющей социально - биографического портрета. Разграничение ассоциаций в зависимости от пола испытуемых и сравнение их с общими “смешанными” нормами из тезауруса способствовало доказательству гипотезы о существовании полового диморфизма в речевой деятельности русскоязычных коммуникантов и помогло выявлению и описанию особенностей мужского и женского вербального поведения (Горошко 1996). Показав, что половому диморфизму подвержена собственно языковая способность человека (в частности вербальное ассоциативное поведение), мы как бы априори смогли доказать его предполагаемое влияние гендерного фактора на все уровни языковой структуры.
Словарь может стать полезным и для преподавателей русского языка и прежде всего русского как иностранного, редакторам и корректорам, т.е. всем тем, кто профессионально занимается субъективной формой существования русского языка. Так, для преподающего русский язык иностранцам и изучающим русский язык как иностранный отнюдь не бесполезной могла бы быть информация по реализации всех значений того или иного многозначного стимула, его синонимические, антонимические, паронимические и омонимические отношения, семантическая сочетаемость. Причем анализ, предоставляемый тезаурусом информации, может производиться как по уровням языковой структуры, так и по типам единиц когнитивного уровня (фразеология, клише, афоризмы) и разновидностям единиц прагматикона (Караулов 1994б). Для изучающего русский язык каждая статья тезауруса есть некий фрейм, набор всех словосочетаний, воспроизводимый в стандартной речи носителями языка. Она может стать объектом научения, речевой моделью, которую надо выучить и свободно использовать в речи. В будущем крайне интересной представляется задача создания специальной ассоциативной методики на базе словаря для обучения речевым моделям русского языка с максимальной опорой на ассоциативную память человека.
Заслуживает внимание и опыт работы с материалами АТСРЯ в аспекте проблемы формирования вторичной языковой личности (Липовска 1997, с.96). Цель исследования А. Липовской была довольно прагматична. Она хотела ответить на вопрос, что полезного болгарский студент – русист может извлечь из тезауруса для «формирования» прагматикона, тезауруса и лексикона вторичной языковой личности? А предметом исследования в формулировке самого автора была проверка:
умения студентов демонстрировать реализацию значений слов - стимулов в виде словосочетаний и предложений, полученных из стимула и реакции;
умения студентов извлекать из статьи грамматическую информацию;
умения студентов извлекать из словарной статьи экстралингвистическую информацию;
формирования сопоставительных навыков при оценке развитии болгарской и русской языковых личностей (Липовска 1997, с.96).
Эксперимент показал настоятельную необходимость в создании русско-болгарского ассоциативного словаря, где данные АТСРЯ составили одну из предполагаемых составляющих такого двуязычного ассоциативного словаря.
А вот для редактора или же корректора, наверное, самая нужная информация из тезауруса может быть извлечена из той совокупности ошибок (стилистических и орфографических), которые были допущены информантами при заполнении анкет. Она для них может стать своего рода вероятностным прогнозом тех мест в речи, где скорее всего может быть допущено нарушение культурно-речевых норм, позволяя предвидеть те места, где могут быть ошибки, с которыми корректоры могут столкнуться при написании или же правки текста.
Но, наверное, в силу того, что информация, содержащаяся в тезаурусе, отражает интуитивное знание носителей языка, “обнажая скрытый от прямого наблюдения способ держания языка в памяти его носителя, обнажая таинственную завесу над святая святых, над тем, как устроена языковая способность человека” (Караулов 1994б, с. 191), то самым полезным такой словарь должен стать для лингвистов. Для них он принципиально новый источник лингвистической информации и инструмент для описания и изучения языковой способности человека. Поэтому и масштаб исследовательских задач, которые могут решаться на базе тезауруса, огромен. Рамки данной работы не позволяют подробно остановиться и описать все то множество задач, которые могут быть решены лингвистами на базе ассоциативного тезауруса русского языка, да и это не нужно, т.к. подробнейший анализ постановки и направлений работы лингвистов с таким словарем был сделан в послесловии к изданию первой книги тезауруса. Да и не под силу одному человеку сформулировать сразу все задачи, которые могут быть решены на основе тезауруса. В самой постановке идеи всегда, во-первых, заложен некий алгоритм её реализации, а, во-вторых, сама идея - это уже своего рода открытие, а один человек не может сразу открыть и предусмотреть всё, поэтому в рамках этой работы мы ограничимся лишь перечислением тех направлений, по которым может развиваться лингвистическая мысль дальше.
Основываясь на предположении, что корпус тезауруса представляет собой АВС, моделирующую устройство языковой способности человека, мы попытаемся выделить основные совокупности задач, в зависимости от уровня языковой способности, отражающей разные свойства самого массива, и в какой-то степени репрезентирующей модели исследовательских подходов в языкознании (см. подробнее Караулов 1994).
Во-первых, существует блок задач, связанный со свойствами собственно всего корпуса тезауруса. Это, например, создание ассоциативного фразеологического словаря или же русского ассоциативного ономастикона на базе реакций тезуруса, составление страноведческого словаря и словаря прецендентных текстов русской культуры. Особо интересной представляется задача создания ассоциативных словарей какой-либо большой социальной группы людей, объединяемых по определенному социально-биографическому или же иному признаку, например, ассоциативный тезаурус мира современной русской женщины.
В отдельную группу можно выделить задачи по изучению статистической структуры ассоциативно-вербальной сети: проверка гипотезы о золотом сечении в структуре ассоциативного поля, установление определенных закономерностей в частотах реакций, их энтропии и стереотипности, и, наконец, самой масштабной могла бы быть задача, связанная с дальнейшим доказательством знаменитого предположения Дж. Диза о замыкаемости круга реакций примерно на седьмом шаге (или же на числе 7 +2) (Deese 1966). А идея Диза заключалась в следующем: если на втором шаге свободного ассоциативного эксперимента в качестве стимульных слов взять самые частотные реакции, полученные на стимулы на первой стадии эксперимента, а затем на третьем шаге использовать в качестве стимулов самые частотные реакции второго этапа и так далее, то самые частотные реакции должны совпасть с исходными стимульными словами на седьмом (плюс/минус два) шаге. А это в свою очередь косвенно доказало бы связь между ассоциативным механизмом и оперативной памятью человека, способной удерживать одновременно: семь (плюс/минус два) единиц информации.
Для лингвистов, а также культурологов заслуживают внимания задачи, связанные с изучением наивной “картины мира” русских. На базе ассоциативных полей можно попытаться установить, к какому члену оппозиций, характеризующих концепцию мира в языке (время/пространство, норма/аномалия, свое/чужое и т.д.), тяготеют реакции, создавая тем самым специфический образ мира в сознании русского. Аналогично этому можно построить символическую картину цветового пространства в русском языке, исходя из ассоциативных полей реакций, полученных на цветонаименования. На базе словаря могут решаться и задачи, связанные с гендерной проблематикой, т.к. в компьютерной базе словаря хранится информация о некоторых психофизиологических данных респондентов: поле, возрасте, профессии и т.д., то можно попытаться описать особенности мужского и женского языкового сознания – его аппозитивность и конгруэнтность, проследить динамику развития половозрастных стереотипов.
Автором данной работы была проведена серия ассоциативных экспериментов и собраны нормы специфических групп русскоговорящего населения Украины – людей, находящихся в условиях добровольной или вынужденной изоляции (монастырей, исправительно-трудовых учреждений (колоний) и хосписов). Ассоциативные нормы были собраны на стимульные списки слов, описывающие основные базовые ценности и этико-моральные категории (Горошко 1998, 1999, 2001). С помощью проведения САЭ мы как бы попытались заглянуть в духовный мир этих людей, который очень часто недоступен для “непосредственного” научного изучения. И в этом исследовании материалы тезауруса послужили уникальным сопоставительным материалом, позволившим лишь при сравнении наших ассоциативных норм с нормами из тезауруса, полученных от обычных носителей русского языка, понять всю специфику картины мира людей, находящихся в столь “особенных” жизненных условиях.
В отдельную группу могут быть выделены задачи исследования вербального лексико-семантического и грамматического уровня языковой способности индивида: например, выявить и описать омонимические отношения, паронимию стимулов и реакций в прямом и обратном словаре, проанализировать и обобщить особенности распределения частей речи в поле реакций в зависимости от стимула и т.д.
На базе тезауруса могут быть поставлены и задачи, выходящие за пределы тезауруса вообще. К ним относятся эксперименты по восстановлению стимулов по заданному ассоциативному полю реакций, построение по данным ассоциативных экспериментов определенных семантических пространств, которые образованы некоторыми эмоциональными и оценочными осями. Например, в кандидатской диссертации по исследованию форм репрезентации цвета в субъективном опыте О.В. Сафуановой была доказана возможность реконструирования исходных названий цветов в русском языке по набору наиболее частотных эмоционально-смысловых ассоциаций на них (Сафуанова 1994).
И, наконец, решение такой глобальной задачи как построение сравнительной славянской лексикологии на ассоциативной основе с привлечением стимулов из тезауруса в качестве исходных для формирования ассоциативных полей во всех 14 литературных славянских языках, наверное, уже близка к своему завершению.
Проведенный анализ и описание структуры и содержания тезауруса показывает, что АТСРЯ в руках исследователей должен полностью раскрыть свои возможности и как самостоятельный исследовательский объект, и как инструмент научного анализа. К этому пожеланию, высказанному Ю.Н. Карауловым, автор полностью присоединяется (АТСРЯ т.Y, с. 6). Хочется только надеяться, что эти “мечты” воплотятся уже в не в столь далеком будущем.
Выводы
Примечание